Este ha sido un año de avances extraordinarios en la investigación e implementación de Inteligencia Artificial (IA). Como nosotros, miramos hacia atrás a nuestra publicación realizada en enero de este año, titulada 'Por qué nos centramos en la IA (y con qué fin)', donde indicábamos nuestras prioridades: liderar y establecer estándares en el desarrollo y envío de aplicaciones útiles y beneficiosas; basarnos en principios éticos enmarcados en valores humanos; y evolucionar nuestros enfoques conforme aprendemos de la investigación, la experiencia, los usuarios y la comunidad. Para nosotros esto significa innovar y ofrecer beneficios ampliamente accesibles a las personas y la sociedad, mitigando al mismo tiempo sus riesgos. Este es un esfuerzo colectivo que implica a nosotros y a otros, incluyendo investigadores, desarrolladores, usuarios (individuales, empresas y otras organizaciones), gobiernos, reguladores y ciudadanos.
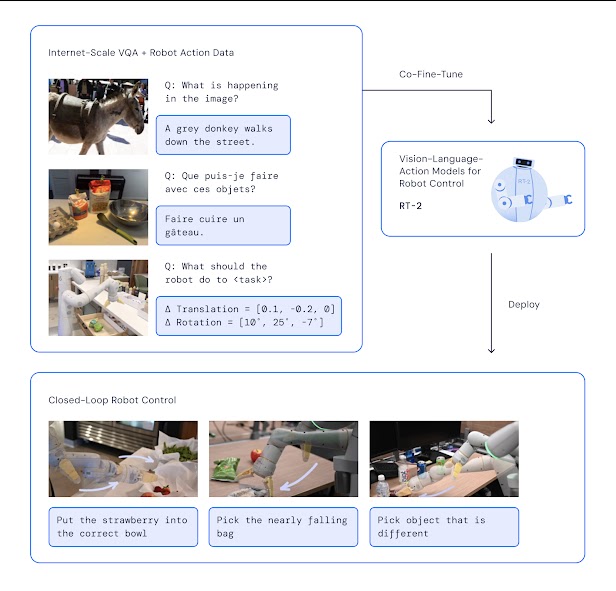
Creemos que las innovaciones en IA que estamos enfocadas en el desarrollo y la prestación de servicios con audacia y responsabilidad pueden ser útiles, convincentes y tener el potencial de ayudar a mejorar la vida de gente en todas partes. En este año revisado vamos a repasar algunos de los esfuerzos de Google Research y DeepMind para poner en práctica estos parárafos durante 2023. Nuestra familia inicial de modelos Gemini se encuentra disponible en tres tamaños distintos: Nano, Pro y Ultra. Los modelos Nano son los más pequeños e eficientes para alimentar experiencias en dispositivos en productos como Pixel. El modelo Pro es altamente capacitado y mejor para escalar a través de una amplia gama de tareas. Por otro lado, el modelo Ultra es nuestro modelo más grande y potente para tareas complejas. Al utilizar algoritmos de aprendizaje automático, podemos enseñar a un modelo las reglas de aritmética mediante un aprendizaje en contexto. En el campo de la respuesta a preguntas visuales, en colaboración con investigadores de UC Berkeley, hemos demostrado cómo podríamos mejorar responder a preguntas visuales complejas (como «¿Es el carro a la derecha del caballo?») combinando un modelo visual con un modelo lingüístico. Actualmente estamos utilizando un modelo general que entiende muchos aspectos del ciclo de vida del desarrollo de software para generar automáticamente comentarios de revisión de código, responder a comentarios de revisión de código, hacer sugerencias de mejora en rendimiento para piezas de código (aprendiendo de cambios previos en otros contextos), fijar el código en respuesta a errores de compilación y más. En una colaboración de investigación multianual con el equipo de Google Maps, hemos sido capaces de escalar el aprendizaje de refuerzo inversa y aplicarlo al problema a nivel mundial de mejorar las rutas, lo que ha resultado en una mejora relativa del 16-24% en la tasa de coincidencia de rutas globales y ayudando a garantizar que las rutas estén mejor alineadas con las preferencias de los usuarios. Además, seguimos trabajando en técnicas para mejorar el rendimiento de inferencia de los modelos de aprendizaje automático. En el trabajo sobre enfoques computacionalmente amigables a las pruning en redes neuronales, hemos sido capaces de diseñar un algoritmo aproximado para solucionar el problema del mejor subconjunto no tabulable computacional que es capaz de podar el 70% de los bordes de un modelo de clasificación de imágenes y todavía conserva casi toda la precisión de la original. En el trabajo de aceleración de modelos de difusión en el dispositivo, también hemos aplicado una variedad de optimizaciones al mecanismo de atención, núcleos convolucionales y fusión de operaciones para que sea práctico ejecutar modelos de generación de imágenes de alta calidad en-dispositivo; por ejemplo, permitiendo «una imagen fotorrealista y de alta resolución de un cachorro lindo con flores circundantes» generada en solo 12 segundos en un smartphone. Los avances en lenguaje capaz y modelos multimodales también han beneficiado nuestros esfuerzos de investigación robótica. Hemos desarrollado modelos de lenguaje, visión y control robótico entrenados en PaLM-E, un modelo multimodal diseñado para la robótica, y Robot Transformer 2 (RT-2), un nuevo modelo de visión-lenguaje-acción (VLA) que aprende tanto de datos web como de robótica y traduce este conocimiento en instrucciones generales para el control robótico.
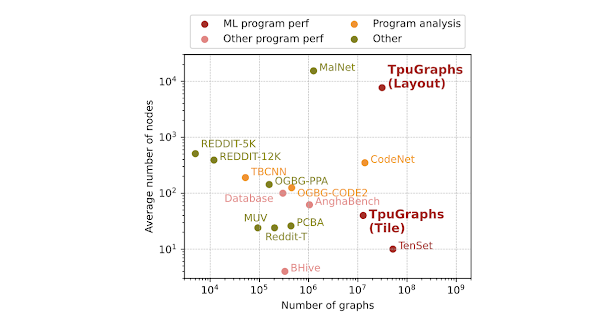
La arquitectura y la formación del RT-2 consisten en ajustar y entrenar un modelo de visión-lenguaje previamente entrenado en robótica y datos web. Este modelo utiliza imágenes de una cámara robot y predice acciones directas para ejecutar un robot. El conjunto de datos TPUGraphs cuenta con 44 millones de gráficos para optimizar el programa ML. Desarrollamos un nuevo algoritmo de balanceo de carga llamado Prequal para distribuir consultas a un servidor y minimizar una combinación, que ha reducido la CPU, latencia y RAM en los despliegues en varios sistemas. También diseñamos un nuevo marco de análisis para el problema tradicional de la caché con reservas de capacidad. Mapas de calor normalizados a Prequal muestran la transición del uso de CPU a las 08:00. Pausa video Reproducir video Contrails fueron detectados en los Estados Unidos utilizando imágenes satelitales de IA y GOES-16. Ver Una selección de predicciones de GraphCast durante 10 días que muestran humedad específica a 700 hectopascales (unos 3 km) sobre la superficie, la temperatura de la superficie y la velocidad del viento superficial. En Salud y Ciencias de la Vida, el potencial de la IA para mejorar los procesos en salud es significativo. El modelo Med-PaLM fue el primer modelo capaz de obtener una puntuación de aprobación en el examen de licenciatura médica de EE.UU., y el modelo PaLM 2 mejoro un 19 % más, con una precisión nivel experto del 86,5%. Estos modelos Med-PaLM están basados en el lenguaje, lo que permite a los médicos hacer preguntas e interactuar sobre condiciones médicas complejas y se han vuelto disponibles para la atención médica organizaciones como parte de MedLM a través de Google Cloud. De manera similar, nuestros modelos lingüísticos generales están evolucionando para manejar múltiples modalidades, mostrando recientemente investigación sobre una versión multimodal de Med-PaLM capaz de interpretar imágenes médicas, datos textuales y otras modalidades, que describe un camino cómo podemos utilizar el potencial emocionante de los modelos de IA para avanzar en la atención clínica mundial. Med-PaLM M es un gran modelo generativo multimodal que codifica e interpreta datos biomédicos de forma flexible, incluyendo datos clínicos, lenguaje, imágenes y genómica con los mismos pesos del modelo. Ejemplos de predicciones de AlphaMissense sobrepuestas en estructuras predichas de AlphaFold (rojo - predicho como patógeno; azul - puntos benignos conocidos). Las puntas rojas representan variantes misensadas patogénicas, las puntas azules representan puntos benignos conocidos.
A la izquierda: proteína HBB. Variaciones en esta proteína pueden causar anemia falciforme. A la derecha: proteína CFTR. Variaciones en esta proteína pueden causar fibrosis quística. Escala de tono de piel monje (MST). Más información en skintone.google. SynthID crea un marco de agua digital imperceptible para imágenes generadas por IA. Una de sus características más utilizadas es 'Explicar error' - cada vez que el usuario encuentra un error de ejecución en Colab, la asistencia de código modelo provee una explicación junto con una solución potencial.