Muchos algoritmos modernos de aprendizaje automático tienen un gran número de parámetros de hiperparámetro. En este artículo, hablamos de la Optimización Bayesiana, un conjunto de técnicas que a menudo se utilizan para ajustar estos parámetros. En general, la optimización bayesiana se puede utilizar para optimizar cualquier función negra-caja. Tomaremos como ejemplo la extracción de oro.
Nuestro objetivo es la obtención de oro en una tierra desconocida. Curiosamente, nuestro ejemplo es similar a uno de los primeros usos del Proceso de Gaussiano (también conocido como kriging), donde el Prof. Krige modeló las concentraciones de oro utilizando un proceso gaussiano. Suponemos que el oro se distribuye alrededor de una línea. Nos gustaría encontrar la ubicación a lo largo de esta línea con el mayor concentrado de oro mientras perforar solo en pocas ocasiones (la perforación es costosa). Supongamos que la distribución de oro se parece a la función siguiente. Es bi-modal, con un valor máximo alrededor de x = 5. No nos preocuparemos del eje X o las unidades del eje Y. Inicialmente, no tenemos idea de la distribución de oro. Puedemos aprender la distribución de oro perforando en diferentes lugares. Sin embargo, esta perforación es costosa. Por lo tanto, queremos minimizar el número de perforaciones necesarias mientras rápidamente encontrar la ubicación con mayor concentración de oro. Problema 1: Mejor estimación de la distribución del oro (Aprendizaje Activo) En este problema, buscamos estimar más precisamente la distribución del oro. No podemos perforar en todos los lugares debido a su alto costo. En cambio, debemos realizar perforaciones solo en aquellos sitios que proporcionen información adicional sobre la ubicación y la concentración de oro. Este problema tiene similitudes con el Aprendizaje Activo. Problema 2: Ubicación del Oro Máximo (Optimización Bayesiana) En este problema, nuestro objetivo es encontrar la ubicación de mayor concentración de oro.
Debido a los costos elevados, no podemos perforar en cada posible localización. En su lugar, debemos realizar perforaciones en aquellas zonas que muestren promesas altas de contener una alta concentración de oro. Esta tarea es similar a la optimización bayesiana. Más adelante, veremos cómo estos dos problemas se relacionan con el Aprendizaje Activo. Para muchos problemas de aprendizaje automático, los datos no etiquetados están disponibles fácilmente. Sin embargo, la etiqueta (o consulta) suele ser costosa. Por ejemplo, para una tarea de discusión a texto, la anotación requiere que expertos la etiqueten manualmente. De igual forma, en nuestra problemática de minería del oro, las perforaciones (como la etiqueta) también son costosas. El aprendizaje minimiza los costes de etiquetado mientras maximiza la precisión del modelado. Este método propondría etiquetar únicamente al punto cuya medida de incertidumbre es más alta. A menudo, la varianza actúa como una medida de incertidumbre. Como solo conocemos el valor verdadero de nuestra función en pocos puntos, necesitamos un modelo sustituto para los valores que nuestra función lleva a otra parte. Este substituto debe ser lo suficientemente flexible como para representar el valor real. Una opción común es utilizar un proceso gaussiano (GP), debido a su flexibilidad y capacidad para brindarnos estimaciones de incertidumbre. El GP admite la configuración de anteriores mediante el uso de núcleos específicos y funciones medias, como el Matern 5/2.
Para más información sobre este tema, consulta el artículo Distill en Gaussian Processes de González. Nuestro modelo sustituto comienza con un anterior de f ( x ) f ( x ) f ( x ), en nuestro ejemplo, elegimos uno que distribuye sin problemas específicos. Evaluamos puntos (perforación), obtenemos más datos para que nuestro substituto aprenda y se actualice según la regla de Bayes. El punto de datos actualiza nuestro modelo sustituto, acercándolo a la verdad del suelo. La línea negra y la región gris sombreada indican la media ( μ ) (μ) e incertidumbre ( μ ± μ). En el ejemplo anterior, empezamos con una incertidumbre uniforme. Pero después de nuestra primera actualización, la posterior es más cercana a x = 0,5 y más incierta lejos de él. Podríamos simplemente seguir agregando más puntos de entrenamiento y obtener una estimación de f ( x ) más segura, pero queremos minimizar el número de evaluaciones. Por lo tanto, debemos elegir inteligentemente el punto de consulta a partir del aprendizaje activo. Aunque hay muchas formas de seleccionar puntos inteligentes, vamos a optar por el más incierto. Esto nos da el siguiente proceso para el Aprendizaje Activo: Elige y agrega al conjunto de entrenamiento el punto con la mayor incertidumbre (preguntando/etiquetando ese punto), entrena en el nuevo conjunto de entrenamiento, continúa hasta la convergencia o presupuesto transcurrido. Ahora vamos a visualizar este proceso y ver cómo nuestros cambios posteriores en cada iteración (después de cada perforación). La visualización muestra que se puede estimar la distribución verdadera en unas pocas iteraciones. Además, la más incierta en cada iteración, el aprendizaje activo explora el dominio para mejorar las estimaciones. Optimización Bayesiana En la sección anterior, seleccionamos puntos para determinar cuál podría ser el punto con mayor contenido de oro.
¿Pero qué pasa si nuestro objetivo es simplemente encontrar la ubicación del máximo contenido de oro? Podríamos hacer un aprendizaje activo para estimar la verdadera función con precisión y luego encontrar su máximo, pero eso parece bastante derrochador... por qué deberíamos usar evaluaciones mejorando nuestras estimaciones de regiones donde la función espera bajo contenido de oro cuando sólo nos preocupamos ¿Sobre el máximo? Esta es la pregunta central en la Optimización Bayesiana: “Basado en lo que sabemos hasta ahora, ¿qué punto debemos evaluar para maximizar nuestras probabilidades? Recordemos que evaluar cada punto es costoso, por lo que queremos elegir cuidadosamente! En el caso de aprendizaje activo y optimización bayesiana, necesitamos equilibrar la exploración de la incertidumbre. Para tomar esta decisión tomamos una función llamada función de adquisición. Las funciones de adquisición son heurísticas, ya que desean evaluar un punto basado en nuestro modelo actual. Más detalles sobre las funciones de adquisición pueden ser accedidos en este enlace. En cada paso, determinamos cuál es el mejor punto para evaluar siguiente es de acuerdo
a la función de adquisición mediante la optimización de la misma. A continuación, actualizar nuestro modelo y repetir este proceso para determinar el siguiente punto a
evaluar. Usted puede estar preguntando qué es “Bayesian” acerca de la optimización bayesiana si sólo estamos optimizando estas adquisiciones
Bueno, en cada paso mantenemos un modelo que describe nuestras estimaciones y la incertidumbre en cada punto, que actualizamos
de acuerdo con la regla de Bayes en cada paso. Nuestras funciones de adquisición se basan en este modelo, y nada sería posible sin
Formalizar la Optimización Bayesiana Introduzcamos ahora formalmente la Optimización Bayesiana. Nuestro objetivo es encontrar la
ubicación ( x â € R d {x \in \mathbb{RÃ3d} x â R d ) correspondiente al máximo (o mà nimo) global de una funciÃ3n f : R d R f:
\mathbb{Red \mapsto \mathbb{R} f : R d R . Presentamos las limitaciones generales en la optimización bayesiana y las contrastamos con
las limitaciones en nuestro ejemplo de extracción de oro La sección a continuación se basa en las diapositivas / charla de Peter Fraizer en Uber en Bayesian
Optimización: . Limitaciones generales Limitaciones en la minería de oro ejemplo f f f ’s factible set A A A es simple, por ejemplo, caja
limitaciones.
Nuestro dominio en el problema de la minería de oro es una restricción de caja unidimensional: 0 ≤ x ≤ 6 0 \leq x \leq 6 0 ≤ x ≤ 6 . f f es continua pero carece de una estructura especial, por ejemplo, la concavidad, que haría que sea fácil de optimizar. ni una función convexa ni cóncava, resultando en óptimos locales. f f f es libre de derivados: las evaluaciones no dan gradiente
información. Nuestra evaluación (por perforación) de la cantidad de contenido de oro en una ubicación no nos dio ninguna información de gradiente. f f f es caro de evaluar: el número de veces que podemos evaluar es severamente limitado. Perforación es costoso. f f f puede ser
ruidoso. Si hay ruido presente, asumiremos que es independiente y normalmente distribuido con variabilidad desconocida. Tomaremos medidas sin ruido en nuestros modelos (aunque se puede añadir ruidonormalmente distribuido en la regresión GP). Para resolver este problema, seguiremos el siguiente algoritmo: Primero elegimos un modelo sustituto para representar la verdadera función f y definir su valor anterior. Dado el conjunto de observaciones (evaluaciones de funciones), utilizar la regla de Bayes para obtener el posterior. Utilizaremos una función de adquisición α ( x ), que depende del posterior, para decidir el siguiente punto de muestra x t = argmax x α ( x ). El conjunto de observaciones y volveremos al paso #2 hasta que la convergencia o presupuesto transcurra. Las funciones de adquisición son cruciales para la optimización bayesiana, y hay una amplia variedad de opciones.
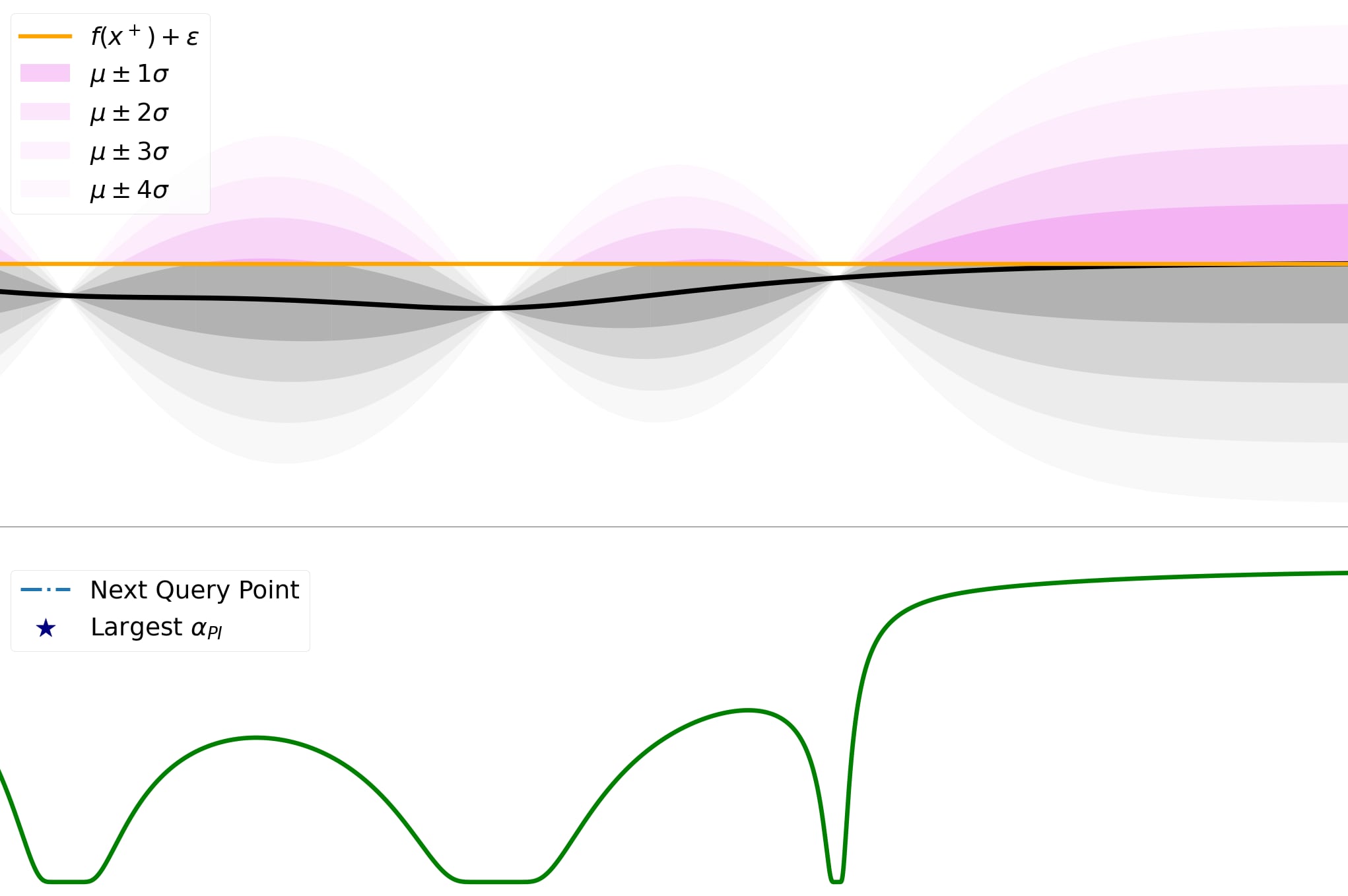
En las siguientes secciones, analizaremos varias opciones proporcionando intuición y ejemplos. Probabilidad de Mejora (PI) Es una función de adquisición que elige el siguiente punto de consulta como aquel que tiene la mayor probabilidad de mejora con respecto al actual. Escribimos la selección del siguiente punto como sigue: x t + 1 = a r g m a x (P(f(x) extgreater= f(x + ) + ε)), donde x + es el siguiente valor de consulta en cada paso de tiempo y x i es la ubicación consultada en el i-ésimo paso. Mirando detenidamente, solo estamos encontrando la probabilidad superior-cola (o el CDF) del sustituto posterior. Además, si usamos un GP como sustituto anterior, entonces x t + 1 = a r g m a x x Φ(μ t ( x ) - f ( x + ) - ε/σ t ( x )), donde μ t ( x ) y σ t ( x ) son las media y desviación estándar del sustituto posterior en el punto x. Las áreas grises indican la probabilidad densa por debajo del máximo actual. La región violeta en cada punto representa la probabilidad de mejorar el máximo actual. Utilizando los criterios de PI (mostrados en línea azul rayada), x = 6, x = 6, x = 6. El uso de epsilon para encontrar un equilibrio entre exploración y explotación, hace que las consultas sean más frecuentes en localizaciones con una mayor dispersión de probabilidad. Ahora veremos la función de adquisición de PI en acción. Comenzamos con 0 = 0, 0 = 0.75. Mirando el gráfico, vemos que alcanzamos el máximo global en solo algunas iteraciones. Los ciclos se rompen aleatoriamente. Nuestro sustituto tiene una gran incertidumbre en x [ 2 , 4 ] (x es entre 2 y 4). La zona gris translúcida identifica la proporción de incertidumbre. Inicialmente, la función de adquisición explota las áreas con alta promesa, lo que conduce a una mayor incertidumbre en el intervalo x â € [ 2 , 4 ] (x es entre 2 y 4).
Esta observación también muestra que no necesitamos construir una estimación precisa de la función black-box para encontrar su máximo. La visualización anterior muestra que el aumento del parámetro a 0.3 nos permite profundizar más en nuestras investigaciones, sin embargo parece que estamos explorando demasiado, lo cual no es deseable ya que estamos empeorando las cosas. Nuestro modelo actual utiliza فارسى = 3 ε = 3σ y no podemos explotar cuando aterrizamos cerca del máximo global. Además, con una alta tasa de exploración el entorno se convierte en similar al aprendizaje activo. Nuestras rápidas pruebas arriba nos ayudan a concluir que el control del nivel de exploración en la adquisición de PI se realiza en un momento dado... Texto parafraseado en español: Por favor, reemplace este texto con una versión traducida y mejorada en idioma español manteniendo el significado original. Texto reescrito en castellano . . . . . . . . . .
. . . . . Texto traducido al español. Texto traducido al castellano Texto traducido o parrafrazeado al castellano Texto reescrito en castellano Texto traducido o reescrito en español... Texto traducido en idioma español Texto traducido y redactado en idioma español Texto traducido al español Texto traducido en español . . . . . . . . .
. . . . . . Texto traducido o reexpresado en castellano Por favor, traduzca el texto en la siguiente forma de formato JSON: . . . . . . . . la función.
La probabilidad de mejora esperada (EI) sólo examinó qué tan probable es una mejora, pero, no lo hizo
El siguiente criterio, llamado Mejora esperada (EI), hace exactamente eso Una buena introducción a
la función de adquisición de mejoras esperadas es por este post de Thomas Huijskens y estas diapositivas de Peter Frazier ! La idea
es bastante simple — elegir el siguiente punto de consulta como el que tiene la mayor mejora esperada sobre el actual max f ( x
+ ) f(x) f(x+), donde x + = argmax x i .» x 1 : t f ( x i ) x = \text{argmax}_{x_i \in x_{1:tâf(x_i)
x+=argmaxxi x1:t f(xi) y x i x_i xi es la ubicación consultada en el paso de tiempo de i t h Í } . En esta adquisición
función, t + 1 t h t + 1o} t+1o punto de consulta, x t + 1 x_{t+1} xt+1 , se selecciona de acuerdo con la siguiente ecuación. x t
+ 1 = a r g m i n x E ( â € € h t + 1 ( x ) − f ( x â € € € € € ~ D t ) x_{t+1} = argmin_x \mathbb{E} \left( h_{t+1}(x) - f(xâ € estrella)
\ \ \ \ mathcal{D}_t \right) x t + 1 = a r g m i n x E ( â € ~ h t + 1 ( x ) − f ( x â € ~ ~ ~ D t ) Donde, f f es
la función real de la verdad del suelo, h t + 1 h_{t+1} ht+1 es la media posterior del sustituto en t + 1 t h t+1} t+1a
timestep, D t \mathcal{D}_t Dt es los datos de formación { ( x i , f ( x i ) ) } { } { } x x 1 : t { x_i, f(x_i)) { \ \ forall x \in
x_{1:t} {(xi ,f(xi))}
están tratando de seleccionar el punto que minimiza la distancia al objetivo evaluado al máximo. Desafortunadamente, no
conocer la función de la verdad de tierra, f f. Mockus propuso la siguiente función de adquisición para superar el problema. x t + 1 = a
r g m a x x E ( m a x { 0 , h t + 1 ( x ) − f ( x + ) } D t ) x_{t+1} = argmax_x \mathbb{E} \left( {max} • 0, \ h_{t+1}(x) -
f(x) \ \ \mathcal{D}_t \right) x t + 1 = a r g m a x x E ( m a x { 0 , h t + 1 ( x ) − f ( x + ) } D t ) x t
+ 1 = a r g m a x x E ( m a x { 0 , h t + 1 ( x ) − f ( x + ) } D t ) \begin{alineado} x_{t+1} = \ & argmax_x \mathbb{E}
\left( {max} {0, \ h_{t+1}(x) - f(x) \ \ \ mathcal{D}_t \right) \end{alineado} x t + 1 = a r g m a x x E ( m a x {
0 , h t + 1 ( x ) − f ( x + ) } D t ) donde f ( x + ) f ( x ) f ( x + ) es el valor máximo que se ha encontrado así
Esta ecuación para GP sustituto es una expresión analítica que se muestra a continuación. La función de esperanza esperada EI (x) se define como sigue: EI(x) = { [(\mu_t(x) - f(x + ) - \epsilon)y \sigma_t(x)] + \sigma_t(x)f(Z), si \sigma_t(x) > 0; 0, si \sigma_t(x) = 0. Aquí, \Phi(l) representa la función de distribución acumulada y \phi(l) la función de densidad de probabilidades. A partir de esta expresión podemos ver que la mejora esperada será alta cuando el valor esperado de \mu_t(x) - f(x+) es alto o cuando la incertidumbre t (x) en torno a un punto es alta. Como la función de adquisición de PI, también podemos regular la cantidad de exploración en la función de adquisición de EI mediante la modificación de la función de Epsilon. Por ejemplo, para \epsilon = 0.01, nos acercamos a los máximos globales en pocas iteraciones. A medida que aumentamos el valor de \epsilon (por ejemplo hasta \epsilon = 0.3), la función de adquisición explora más y se evita más la explotación, aunque también no se explota para obtener más ganancias cerca del máximo global. El entrenamiento utilizado durante la elaboración de la sección solo consiste en una sola observación (0,5, f(0,5)). Se observa que αEI y αPI alcanzan un máximo de 0,3 y aproximadamente 0,47, respectivamente. Es preferible elegir un punto con baja αPI y alta αEI debido a que esto implica alto riesgo, ya que la probabilidad de mejora es baja y la recompensa esperada es alta.
En caso de varios puntos con el mismo αEI, priorizar el punto de menor riesgo (más alto αPI). Si el riesgo es igual, elegir el punto con mayor recompensa (mayor αEI). Thompson Sampling es otra función de adquisición común. En cada paso, se muestra una función posterior del sustituto y se optimiza. Por ejemplo, en el caso de la extracción de oro, se presenta una distribución plausible del oro dada la evidencia y se evalúa (perforación) en cualquier lugar que picos. Adjunto una imagen que muestra tres funciones de muestreo de sustituto aprendido posterior para nuestro problema de extracción de oro. Los datos de entrenamiento constituyeron el punto x = 0,5 y el valor correspondiente de la función. La intuición detrás del Thompson Sampling se puede entender por dos observaciones: Las ubicaciones con alta incertidumbre mostrarán una gran variabilidad en los valores funcionales, lo que significa que hay una probabilidad no trivial de que una muestra tome un valor alto en una región altamente incierta. Optimizar tales muestras puede ayudar a la exploración. Por ejemplo, las tres muestras (muestra #1, #2, #3) muestran gran variabilidad cerca de x = 6. La optimización de la muestra 3 ayudará en la exploración a través del análisis de x = 6. Las funciones deben pasar por el valor máximo actual, ya que no hay incertidumbre en las ubicaciones evaluadas. Como ejemplo de este comportamiento, vemos que todas las funciones mostradas arriba pasan a través del valor máximo actual en x = 0,5. Si x = 0,5 estuviera cerca del máximo global, podríamos explotar y elegir un máximo mejor. La visualización anterior utiliza el muestreo de Thompson para la optimización.
En otras palabras, podemos alcanzar el óptimo global en relativamente pocas iteraciones. Además, podemos crear una función de adquisición aleatoria mediante el muestreo de x al azar. Como esa visualización anterior demuestra, el rendimiento de la función de adquisición aleatoria no es tan malo! Sin embargo, si nuestra optimización era más compleja (más dimensiones), entonces la adquisición aleatoria podría fallar. Resumen de las funciones de adquisición: i) son heurísticas para evaluar la utilidad de un punto; ii) son una función de la sustitución posterior; iii) combinan exploración y explotación; iv) son otras funciones de adquisición. Hemos visto varias funciones de adquisición hasta ahora. Para llegar a las funciones de adquisición, es necesario combinar explorar/explotar. Upper Confidence Bound (UCB) es una función de adquisición trivial que combina la exploración/explotación. La intuición detrás de la función de adquisición UCB está en el balance entre la media de la subrogata frente a la incertidumbre de la subrogada. Un periodista analiza las funciones de adquisición en el contexto de la explotación o exploración minera. Puede formar más funciones de adquisición combinando las existentes, aunque la interpretación física de tales combinaciones puede no ser directa. Dos métodos son superar las limitaciones de los métodos individuales. La probabilidad de mejora y el valor del parámetro λ multiplicados por la esperanza de mejoras (EI-PI) pueden ser una combinación lineal de PI y IE, que se enfocan en la probabilidad de mejora y la mejora esperada respectivamente. El proceso gaussiano de alto nivel de confianza (GP-UCB) es un método en el que si el mayor oro era una unidad a y nuestra optimización indica en cambio una ubicación con menos unidades b < a, entonces nuestro arrepentimiento es a − b. Si acumulamos el arrepentimiento sobre n iteraciones, obtenemos la expresión de GP-UCB, que es: α G P − U C B ( x ) = μ t ( x ) + β t t ( x ). Srinivas y otros desarrollaron un programa teóricamente para minimizar la acumulación de arrepentimientos.
Comparando el desempeño de diferentes funciones de adquisición en este problema, las diapositivas de Nando De Freitas son una herramienta valiosa. Hemos utilizado los parámetros óptimos para cada función de adquisición y ejecutamos la función aleatoria varias veces con diferentes semillas, trayéndonos la media de oro sentido en cada iteración. La estrategia aleatoria es inicialmente comparable o mejor que otras funciones de adquisición como UCB y GP-UCB, sin embargo, el máximo de oro sentido por azar crece lentamente en comparación con las demás funciones de adquisición que pueden encontrar una buena solución en un pequeño número de iteraciones. Afinación Antes de hablar de la optimización bayesiana para la afinación hiperparamétrica , vamos a diferenciar rápidamente entre
hiperparámetros y parámetros: los hiperparámetros se establecen antes de aprender y los parámetros se aprenden de los datos. Ilustramos la diferencia, tomamos el ejemplo de regresión de Ridge. • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • •
x_i^T\theta \right)^2 + \lambda \sum\limits_{j=1\p} \theta^2_j
2 • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • • •
\begin{alineado} \hat{theta}_{ridge} = & argmin_{theta\ \in \ \mathbb{R} \sum\limits_{i=1\n} \left(y_i - x_i^T\theta
\derecha)^2 ^ & + \lambda \sum\limits_{j=1\p} \theta^2_j \end{alineado} ^ ^ r i d g e = a r g m i n
y i − x i T فارسى ) 2 +
Coeficiente de regularización ≥ 0 \lambda \geq 0 0 es el hiperparametro. Si resolvemos el problema de regresión anterior vía
optimización de descenso de gradiente, introducimos más adelante otro parámetro de optimización, la tasa de aprendizaje α \alpha α.
caso de uso común de la Optimización Bayesiana es ajuste hiperparamétrico: encontrar los hiperparametros de mejor rendimiento en la máquina
modelos de aprendizaje. Cuando la formación de un modelo no es caro y requiere mucho tiempo, podemos hacer una búsqueda en cuadrícula para encontrar el óptimo
hiperparametros. Sin embargo, la búsqueda en cuadrícula no es factible si las evaluaciones de la función son costosas, como en el caso de una gran
red que tarda días en entrenar. Además, escalas de búsqueda de cuadrícula pobre en términos de número de hiperparametros. Optimización bayesiana para contrarrestar el carácter costoso de la evaluación de nuestra función de caja negra (exactitud). Vector Machine (SVM) En este ejemplo, utilizamos una SVM para clasificar en el conjunto de datos de las lunas de sklearn y utilizar la Optimización Bayesiana para
optimizar los hiperparametros SVM. γ \gamma γ — modifica el comportamiento del núcleo de SVM. Intuitivamente es una medida de la
influencia de un solo ejemplo de entrenamiento StackRespuesta de exceso de flujo para la intuición detrás de los hiperparámetros. .
— modifica el
comportamiento del núcleo de la SVM. Intuitivamente es una medida de la influencia de un solo ejemplo de entrenamiento . C C C — modifica el
flaqueza de la clasificación, cuanto más alto es el C C C, más sensible es SVM hacia el ruido. Veamos ahora los datos que tenemos, que tienen dos clases y dos características. Vamos a aplicar la optimización bayesiana para encontrar los mejores hiperparámetros en este problema de clasificación. Nota: las superficies mostradas para las Exactitudes del Terreno a continuación fueron calculadas para cada punto, pero no se encuentran estos valores en aplicaciones reales. Los óptimos para C , γ C y γC se obtuvieron mediante la búsqueda de cuadrícula ejecutada con gran grano. Arriba podemos observar una barra deslizante que muestra el trabajo de la función de adquisición de Probabilidad de Mejora en la búsqueda de los mejores hiperparámetros. También podemos ver la función de adquisición esperada en la búsqueda de los mejores hiperparámetros y compara diferentes funciones de adquisición. Ejecutamos la función de adquisición aleatoria varias veces para promediar sus resultados. Toda nuestra adquisición sobrepasó a la adquisición aleatoria después de siete iteraciones. Podemos ver que el método aleatorio parecía realizar mucho mejor al principio, pero no pudo alcanzar el óptimo global, mientras que la optimización bayesiana se acercó considerablemente. El rendimiento inicial deficiente de la Optimización Bayesiana puede atribuirse a la exploración inicial. — Ahora utilizaremos un bosque aleatorio con optimización bayesiana en un clasificador forestal aleatorio. Ahora empezaremos a entrenar un bosque aleatorio usando el conjunto de datos de lunas que habíamos utilizado anteriormente para aprender el modelo de Vector Support Machine.
Nuestros objetivos son optimizar nuestra precisión, lo que significa que queremos conocer cuántos árboles de decisión deseamos tener y qué profundidad máxima desearíamos en cada uno de ellos. Se utilizan procesos gaussianos con un núcleo Matern para estimar y predictir la función de precisión sobre dos hiperparámetros. La optimización bayesiana típica se lleva a cabo mediante la función de adquisición de Probabilidad de Mejora. Aquí vemos una ejecución que muestra el funcionamiento de la función de adquisición de mejora esperada en la optimización de los hiperparámetros. Ahora se utiliza la función de adquisición de confianza limitada para la optimización de los hiperparámetros. Vamos a utilizar ahora la función de adquisición aleatoria. Las estrategias de optimización parecían tener dificultades en este ejemplo, lo que podría atribuirse a la rugosidad de la verdad no suave. La eficiencia de la Optimización Bayesiana depende de la eficiencia del sustituto para modelar la función real de caja negra. Es interesante observar que el marco de optimización bayesiana aún supera a la estrategia aleatoria utilizando varias adquisiciones. Este ejemplo se refiere a Redes Neuronales, para ver cómo se aplica la optimización bayesiana al entrenamiento de redes neuronales. Aquí vamos a utilizar scikit-optim, que también nos proporciona soporte para optimizar la función con un espacio de búsqueda de variables categóricas, integrales y reales. No se traza la verdad de la tierra aquí, ya que es extremadamente costoso hacerlo. A continuación se presentan algunos fragmentos de código que muestran la facilidad de usar paquetes de optimización bayesiana para sintonizar el hiperparámetro. Primero declara un espacio de búsqueda para el problema de optimización. Para limitar el espacio de búsqueda, seleccionamos los siguientes valores: batch_size — Este hiperparámetro establece el número de ejemplos de entrenamiento a combinar para encontrar los gradientes en un solo paso del descenso de gradiente.
El valor de tamaño del lote es 2. En nuestro espacio de búsqueda para los posibles tamaños de lotes, nos centraremos en valores enteros que cumplan con esta condición (batch_size = ...). Este hiperparámetro define el stepsize con el que realizaremos el descenso del gradiente en la red neuronal. Estaremos buscando en todos los números reales en el rango [10e-6, 1]. También tendremos una variable categórica (activación) para aplicar a nuestras capas de red neuronal. Esta variable puede tomar valores entre 'relu' y 'sigmoid'. Además, estaremos usando la función minimizadora de scikit-optim para realizar la optimización. A continuación mostramos su llamado a través del optimizador utilizando la mejora esperada, aunque podemos seleccionar otras funciones de adquisición. El gráfico superior muestra el mejor resultado hasta ahora (eje y) y el número de evaluaciones (eje x). En este artículo, vamos a abordar la optimización bayesiana como método de optimización de una función desconocida. La optimización bayesiana se muestra muy útil cuando las evaluaciones de la función son costosas, lo que hace poco práctico utilizar cuadrícula o búsqueda exhaustiva. Primero examinaremos la idea de usar una función suplente para modelar nuestra función desconocida. Las evaluaciones de la función se utilizan como datos para obtener el sustituto posterior. Las funciones de adquisición, que son funciones del sustituto posterior y se optimizan secuencialmente, también se analizarán. La optimización es costosa, por lo que es útil para nosotros.
Además, examinaremos algunas funciones de adquisición e intentaremos mostrar cómo estos diferentes tipos de funciones mantienen un equilibrio entre exploración y explotación. Finalmente, examinaremos algunos ejemplos prácticos de optimización bayesiana para optimizar los hiperparámetros de los modelos de aprendizaje automático. Esperamos que le haya gustado leer el artículo y que esté listo para explotar el poder de la optimización bayesiana. En caso de que desee explorar más, por favor, revisa la sección de lectura adicional siguiente. También brindamos nuestra biblioteca para reproducir el artículo completo.