Tecnologías que generan audio para videos: avances. La investigación de video a audio utiliza píxeles de video y mensajes de texto para crear bandas sonoras ricas. Los modelos de generación de video han avanzado a un ritmo increíble, pero muchos sistemas actuales solo pueden producir una salida silenciosa. Sin embargo, las películas generadas a la vida están creando bandas sonoras para estos videos mudos.
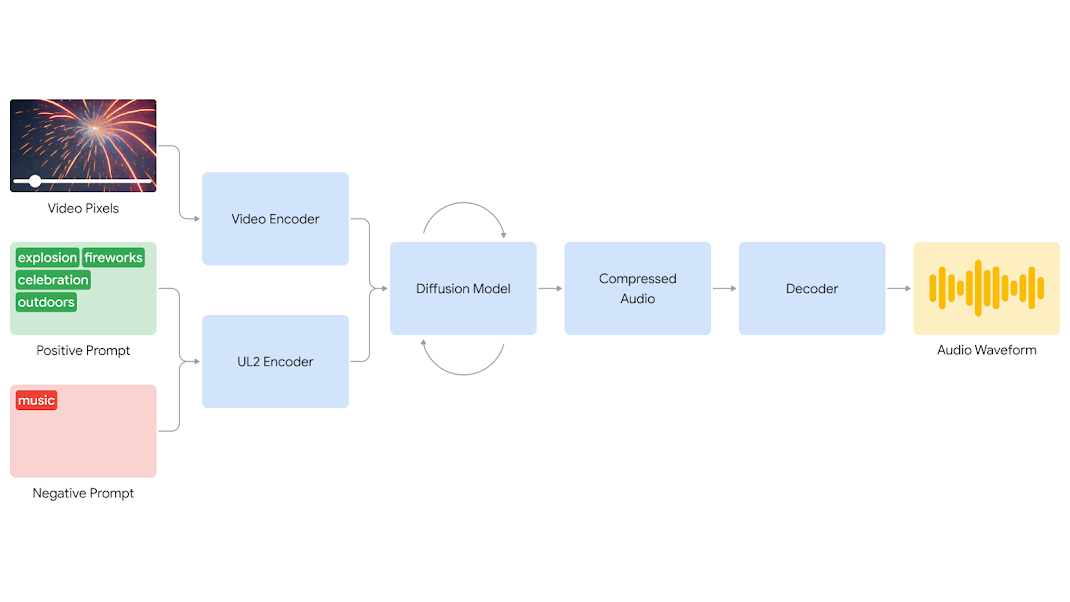
Hoy en día, compartimos el progreso de nuestra tecnología V2A, que permite la generación audiovisual sincronizada. V2A combina píxeles de video con texto en lenguaje natural y anima a generar paisajes sonoros ricos para la acción en pantalla. Nuestra tecnología V2A es compatible con modelos de generación de video como Veo, lo que permite crear tomas con una partitura dramática, efectos de sonido realistas o diálogo que coincidan con los personajes y el tono del video. También puede generar bandas sonoras para un rango de material tradicional, incluyendo archivo de material, películas mudas y más - abriendo una gama más amplia de oportunidades creativas. Prompt para audio: Cine, thriller, película de terror, música, tensión, ambiente, pasos concretos; Prompt para audio: Lindo bebé dinosaurio que trinuda, ambiente de la selva, huevo que se rompe rápidamente; Prompt para audio: Medusa pulsando bajo el agua, vida marina, océano; Prompt para audio: Un baterista en un escenario en un concierto rodeado de luces intermitentes y una multitud de aplausos; Prompt para audio: Autos que deslizan, motor de carro estrangulamiento, música electrónica angelical; Prompt para audio: Una armónica lenta y suave que se juega mientras el sol se pone en una pradera; Prompt para audio: Lobo que aulla a la luna. Control creativo mejorado: Es importante destacar que V2A puede generar un número ilimitado de bandas sonoras para cualquier entrada de video. ‘prompt positivo’ se puede definir para guiar la salida generada hacia los sonidos deseados, o un ‘prompt negativo’ para guiarlo hacia fuera de sonidos no deseados. Esta flexibilidad da a los usuarios más control sobre la salida de audio de V2A, lo que permite experimentar con diferentes salidas de audio y elegir la mejor combinación. Prompt para audio: Una nave espacial atraviesa la inmensidad del espacio, estrellas que pasan por encima de él, alta velocidad, ciencia ficción; Prompt para audio: Ambiente etéreo de violonchelo; Prompt para audio: Una nave espacial atraviesa la inmensidad del espacio, las estrellas rayas más allá de ella, alta velocidad, ciencia ficción. Cómo funciona: Hemos experimentado con enfoques autorregresivos y de difusión para descubrir la arquitectura de IA más escalable, y el enfoque basado en la difusión para la generación de audio dio los resultados más realistas y convincentes para sincronizar vídeo y audio. Nuestro sistema V2A comienza codificando la entrada de video en una representación comprimida. A continuación, el modelo de difusión refina iterativamente el audio del ruido aleatorio. Este proceso se guía por la entrada visual y las indicaciones de lenguaje natural dadas para generar audio sincronizado con el video subyacente. Primero, la tecnología V2A codifica y ejecuta iterativamente el prompto de video y audio a través del modelo de difusión. Genera audio comprimido que se decodifica en una forma ondulatoria del sonido.
Para mejorar la calidad del audio y capacitar al modelo para generar sonidos específicos, se agrega información adicional sobre el proceso de entrenamiento, incluyendo descripciones detalladas del sonido y transcripciones del diálogo hablado. A través de la formación en video, audio y anotaciones, nuestra tecnología aprende a asociar audio específico con varias escenas visuales, mientras responde a la información proporcionada en las anotaciones o transcripciones. En curso Nuestras investigaciones se distinguen de las soluciones existentes de video a audio porque puede comprender píxeles crudos y agregar un prompto de texto es opcional. Además, el sistema no necesita la alineación manual del sonido generado con el vídeo, lo que implica la tediosa sincronización diferentes elementos de audio, visuales y cronometrajes. Sin embargo, hay una serie de limitaciones que estamos tratando de abordar y más investigación está en curso. La salida de audio depende de la calidad del ingreso de video y cualquier artefacto o distorsión que no estén dentro del ámbito de entrenamiento del modelo pueden conducir a una importante disminución de la calidad del audio. Además, estamos mejorando la sincronización de labios para que V2A genere voz partiendo de las transcripciones de entrada y sincronizarlas con el movimiento de los labios de los personajes, pero el modelo de generación de video puede no estar condicionado en transcripciones. Esto crea un desajuste que a menudo resulta en una sincronización de labios extraña ya que el modelo de video no genera movimientos bucales que coincidan con la transcripción. Prompt para audio: Música, Transcripción: 'Este pavo se ve increíble, tengo mucha hambre'. Nuestro compromiso es el desarrollo y despliegue responsable de tecnologías de IA. Nosotros estamos reunidos con diversas perspectivas y opiniones de creadores y directores de cine líderes y utilizamos esta valiosa retroalimentación para informar a nuestra investigación y desarrollo en curso. Utilizamos nuestro kit de herramientas SynthID en nuestra investigación V2A para marcar todo el contenido generado por IA para ayudar a proteger contra su posible uso indebido. Antes de considerar la apertura de acceso público general a ella, nuestra tecnología V2A muestra prometedoras perspectivas. Para darle vida a las películas generadas. Nota: Todos los ejemplos son creados por nuestra tecnología V2A, que es compatible con Veo, nuestro modelo de generación de video más capaz.