En los últimos años, el aprendizaje de refuerzo (RL) ha avanzado notablemente, incluyendo derrotar a jugadores del campeón mundial Go, controlando manos robóticas y hasta pintar cuadros. Uno de los principales desafíos en RL es la estimación de valor – aprender las consecuencias a largo plazo de estar en un estado, lo que es difícil debido a que los retornos futuros son generalmente ruidosos e influidos por muchas otras cosas. En el futuro, si se logra esto, pero aunque sea difícil, estimar el valor también es fundamental para muchos enfoques de RL. Para muchos enfoques (iteración del valor de las políticas), la estimación del valor es casi todo el problema, mientras que en otros enfoques (modelos crítico-actor), la estimación del valor es fundamental para reducir el ruido.
La forma más natural de estimar el valor de un estado es como la media de retorno observada de ese estado. Cliff World es un clásico ejemplo de RL, donde el agente aprende a caminar por una costa para llegar a una meta. En otras ocasiones se usa la estimación Monte Carlo sobre trayectorias en las que se cruzan. Si un estado solo es visitado en un episodio, Monte Carlo dice que su valor es el retorno de ese episodio. De lo contrario, Monte Carlo estima su valor como la media sobre ellos. Vamos a explicar Monte Carlo un poco más formalmente. En RL, a menudo describimos algoritmos con reglas de actualización, que nos dicen cómo cambiar las estimaciones con un episodio adicional. Utilizaremos el operador de Más específicamente, el n t
h La actualización de Monte Carlo es V ( s t ) = V ( s t − 1 ) + 1 n [ R n − V ( s t ) ] V(s_t) = V(s_{t-1}) + \frac{1} \bigr[
R_{n} - V(s_t) \bigl] V(st)=V(st−1)+n1 [Rn −V(st)] y podríamos usar la notación “+=”. aproximadores de la función paramétrica tales como redes neuronales, nuestro operador de “actualización hacia” puede representar un paso de gradiente, que
no se puede escribir en la notación “+=”. Con el fin de mantener nuestra notación limpia y general, elegimos utilizar la \hookleftarrow
operador durante todo el tiempo. V ( s t ) V(s_t)
El término a la derecha se llama el retorno y lo usamos para medir la cantidad de recompensa a largo plazo que gana un agente. sólo una suma ponderada de recompensas futuras r t + γ r t + 1 + γ 2 r t + 2 + . . r_{t} + \gamma r_{t+1} + \gamma^2 r_{t+2} + ...
rt rt+1 2rt+2 +... donde γ \gamma γ es un factor de descuento que controla cuánto recompensas a corto plazo valen en relación con
recompensas a largo plazo. La estimación de valor mediante la actualización hacia el retorno tiene mucho sentido.
Después de todo, la definición de valor es
Puede ser sorprendente que podamos hacerlo mejor. Golpeando a Monte Carlo
¡Pero podemos hacerlo mejor! El truco es usar un método llamado aprendizaje de Diferencia Temporal (TD), el cual arranca fuera de las cercanías. estados para hacer actualizaciones de valor. V ( s t ) V ( s_t ) V ( s t ) V ( s ) \hookleftarrow r t r_{t} r t + + γ V ( s t + 1 ) \gamma V(s_{t+1} γ V ( s t + 1 )
Valor de estado Recompensa Valor de estado siguiente
Las intersecciones entre dos trayectorias se manejan de manera diferente bajo esta actualización. A diferencia de Monte Carlo, las actualizaciones TD se fusionan
intersecciones para que el retorno fluya hacia atrás a todos los estados anteriores. A veces el agente alcanza su objetivo, otras veces cae del acantilado. El aprendizaje TD fusiona caminos donde se cruzan. ¿Qué significa “fusionar trayectorias” en un sentido más formal? ¿Por qué podría ser una buena idea? Una cosa a notar es que V ( s
t + 1 ) V(s_{t+1}) V(st+1 ) se puede escribir como la expectativa sobre todas sus actualizaciones TD:
V ( s t + 1 ) V(s_{t + 1})V ( s t + 1 ) \simeq E [ r t + 1 ′ + γ V ( s t + 2 ′ ) ] \mathop{\mathbb{E \bigr[ r’_{t+1}
\gamma V(s)_{t+2} \bigl] E [ r t + 1 ′ + γ V ( s t + 2 ′ ) ] \simeq E [ r t + 1 ′ ] + γ E [ V ( s t + 2 ′ ) ]
\mathop{\mathbb{E} \bigr[ r’_{t+1} \bigl] \gamma \mathop{\mathbb{E} \bigr[ V(s’_{t+2}) \bigl] E [ r t + 1 ′ ] + γ E [
V ( s t + 2 ′ ) ]
Ahora podemos usar esta ecuación para expandir la regla de actualización de TD recursivamente:
V ( s t ) V(s_t)~ V ( s t ) V(s ) \hookleftarrow~ r t r_{t} r t + + γ V ( s t + 1 ) \gamma V(s_{t+1}) γ V ( s t + 1 )
\hookleftarrow~ r t r_{t} r t + + γ E [ r t + 1 ′ ] \gamma \mathop{\mathbb{E} \bigr[ r’_{t+1} \bigl] γ E [ r t + 1 ′ ]
+ + + γ 2 E [ V ( s t + 2 ′ ′ ) ] \gamma^2 \mathop{mathbb{E\bigr[ V(s’_{t+2}) \bigl] γ 2 E [ V (s t + 2 ′ ′ ) ]
\hookleftarrow~ r t r_{t} r t + + γ E [ r t + 1 ′ ] \gamma \mathop{\mathbb{E} ~ \bigr[ r’_{t+1} \bigl] γ E [ r t + 1 ′
] + + γ 2 E E [ r t + 2 ′ ′ ] \gamma^2 \mathop{\mathbb{EE} ~ \bigr[ r’_{t+2} \bigl] γ 2 E E [ r t + 2 ′ ′ ] + + . . . . .
. . . . . . . Texto traducido o reexpresado en español Texto reescrito en castellano Texto traducido al idioma español Texto parafraseado en español: ¿Por favor, responde solo utilizando el siguiente formato de JSON: Texto parafraseado en español: Información sobre el desastre ecológico ocurrido en la costa oriental de América del Norte, que se atribuye al derrame de petróleo desde un barco. Texto traducido al español . . . . . . .
. . . . . . . . Texto traducido y parrafiado al español Texto traducido al castellano Texto reescrito en español Texto parafraseado en español: ¿Por favor, responda solo en el formato de JSON siguiente: Texto reexpresado en español Texto traducido al español Texto traducido al español Traducción parafraseada del texto en español Texto parafraseado en español: El artículo analiza el impacto del cambio climático en las corrientes marinas del Pacífico norte. Los científicos han observado que esta región sufre una disminución de la productividad biológica, con consecuencias para la vida silvestre y los recursos pesqueros. . . . . .
. . . . . . . . . . Texto traducido o redactado en español, manteniendo el significado original y mejorando la expresión en este idioma. . . . .
. . . . Esto nos da una extraña suma de valores de expectativa anidados. A primera vista, no está claro cómo compararlos con el
más simple de mirar Monte Carlo actualización. Lo más importante, no está claro que debemos comparar los dos; las actualizaciones son tan
diferente que se siente un poco como comparar manzanas con naranjas. De hecho, es fácil pensar en Monte Carlo y TD aprender como dos
enfoques completamente diferentes. Pero no son tan diferentes después de todo. Vamos a reescribir la actualización de Monte Carlo en términos de recompensa y colocarlo al lado de la
ampliación de la actualización TD. MC update V ( s t ) V(s_t)~ V ( s t )
+ γ 2 r t + 2 \gamma^2 ~ r_{t+2} γ 2 r t + 2 + + . Premio de la trayectoria actual. Premio otorgado en base a la ruta presente... Actualización TD V(s_t) es V(s_t) + γ [Esperanza de retorno del tiempo siguiente] multiplicado por γ, y luego se suma la esperanza de retorno del tiempo siguiente, también multiplicada por el cuadrado de γ. Es decir, Actualización TD V(s_t) es V(s_t) + γ * [Esperanza de retorno del tiempo siguiente] + γ^2 * Esperanza de retorno del tiempo siguiente+1 multiplicada por γ y más... Texto traducido y reescrito en español... Texto reescrito en español Texto reescrito en castellano Traducción parafraseada al español Texto traducido o parrafeado al español Texto traducido o reescrito en castellano con mantenimiento del significado original y mejoras de expresión Texto reescrito en castellano Texto traducido al español Texto traducido al español Texto parafraseado en español: Algunos funcionarios de la empresa han sido acusados de corrupción. . .
. . . . . . . . . . . . . Texto reescrito en castellano . .
. . . . . . . . . . . . . Texto parafraseado en español: En un ambiente de continua incertidumbre, es importante enfatizar la necesidad de tomar medidas preventivas y cuidadosas para garantizar el bienestar y la seguridad de los miembros de nuestra comunidad. .
. . . . . . . . . . . . . . Explorando el camino actual.
La expectativa sobre las opciones que podrían intersectar este camino es clave. Es decir, la diferencia entre el aprendizaje de Montecarlo y el de TD se reduce a la expectativa anidada de los operadores. Resulta que hay una buena interpretación visual de lo que están representando. Lo llamamos la perspectiva de las opciones en cuanto a evaluar el aprendizaje. Perspectiva de las vías
A menudo pensamos en la experiencia de un agente como una serie de rutas. La agrupación es lógica y fácil de visualizar. Ruta 1 Ruta 2
Sin embargo, esta forma de organizar la experiencia del agente resalta las relaciones entre las rutas. En cualquier punto en que dos rutas se intersecan, ambos resultados son futuros válidos para el agente. Por lo tanto, incluso si el agente ha seguido la ruta 1 hasta la intersección, podría teóricamente seguir la ruta 2 a partir de ese punto en adelante. Podemos ampliar considerablemente la experiencia del agente utilizando estas simulaciones de rutas o 'caminos'. Camino 1 Camino 2 Camino 3 Camino 4
Valor estimado. Resulta que Monte Carlo está promediando sobre rutas reales, mientras que el aprendizaje TD está promediando sobre todos los valores de expectativa anidados que vimos antes, que corresponden al promedio del agente a través de todas las posibles rutas futuras. Monte Carlo Estimación: Promedios sobre rutas reales
Resultado MC estimación: Diferencia Temporal
Estimación promediada: Sobre posibles rutas que dan lugar a una estimación del TD al comparar los dos. En términos generales, el mejor valor estimado es el que tiene la varianza más baja. Carlo son promedios empíricos, el método que da la mejor estimación es el que promedia sobre más ítems.
pregunta natural: ¿Qué estimador promedia sobre más artículos? V a r [ V ( s ) ] Var[V(s) > V a r [ V ( s ) ] V a r [ V ( ) > \propto > 1 N \frac{1} N 1 Diferencia de estimación Inversa del número
de los artículos en el promedio
En primer lugar, el aprendizaje TD nunca tiene un promedio de menos trayectorias que Monte Carlo porque nunca hay menos simulados
Por otro lado, cuando hay más trayectorias simuladas, el aprendizaje TD tiene la oportunidad de
Esta línea de razonamiento sugiere que el aprendizaje de TD es el mejor estimador y el mejor
ayuda a explicar por qué TD tiende a superar Monte Carlo en entornos tabulares. Introducción de funciones Q
Una alternativa a la función de valor es la función Q. En lugar de estimar el valor de un estado, estima el valor de un
La razón más obvia para usar funciones Q es que nos permiten comparar diferentes acciones. Muchas veces nos gustaría comparar el valor de las acciones bajo una política. Es difícil hacer esto con una función de valor. Es más fácil
utilizar funciones Q, que estiman los valores de acción de estado conjunto. Hay algunas otras propiedades agradables de las funciones Q. Para verlas, vamos a escribir las reglas de actualización de Monte Carlo y TD. Actualizando funciones Q. La regla de actualización de Monte Carlo parece casi idéntica a la que escribimos para V (s ) V(s) V(s):
Q ( s t , a t ) Q(s_t, a_t )
Sin embargo, en lugar de actualizar hacia el retorno de estar en algún estado, nos actualizamos hacia el
retorno de estar en algún estado y la selección de alguna acción. Ahora vamos a tratar de hacer lo mismo con la actualización TD:
Q ( s t , a t ) Q(s_t , a_t )
Q(s_{t+1}, a_{t+1}) γ Q ( s t + 1 , a t + 1 ) Valor de la acción del Estado Recompensa Valor del estado siguiente
Esta versión de la regla de actualización de TD requiere un tupla del formulario ( s t , a t , r t , s t + 1 , a t + 1 ) (s_t, a_t, r_{t},
s_{t+1}, a_{t+1}) (st ,at ,rt ,st+1 ,at+1 ), así que lo llamamos el algoritmo Sarsa. Sarsa puede ser la forma más simple de escribir este TD
actualizar, pero no es el más eficiente. El problema con Sarsa es que utiliza Q ( s t + 1 , a t + 1 ) Q(s_{t+1},a_{t+1})
Q(st+1 ,at+1 ) para el siguiente valor de estado cuando realmente debería estar usando V ( s t + 1 ) V(s_{t+1}) V(st+1 ). Lo que necesitamos es un
mejor estimación de V ( s t + 1 ) V(s_{t+1}) V(st+1 ). Q ( s t , a t ) Q(s_t , a_t ) Q ( s t , a t ) Q ( s t , a t ) \hookleftarrow • r t r r_{t} r t + + γ V ( s t + 1 ) \gamma V(s_{t+1} γ
V ( s t + 1 ) Valor de la acción del Estado Recompensa Valor del estado siguiente V ( s t + 1 ) V(s_{t + 1})V ( s t + 1 ) = = = ?
? ? Hay muchas maneras de recuperar V ( s t + 1 ) V(s_{t+1}) V(st+1 ) de funciones Q. En la siguiente sección, vamos a echar un vistazo de cerca
a cuatro de ellos. Funciones Q de aprendizaje con rutas reponderadas
Sarsa esperada. Una mejor manera de estimar el valor del siguiente estado es con una suma ponderada También escrito como un valor de expectativa,
por lo tanto “Especulado Sarsa”. sobre sus valores Q. Llamamos a este enfoque esperado Sarsa:
Sarsa utiliza el valor Q asociado con una t + 1 a_{t+1} una t + 1 para estimar el valor del siguiente estado. expectación sobre los valores de Q para estimar el valor del siguiente estado. He aquí un hecho sorprendente acerca de la Sarsa esperada: la estimación de valor que da es a menudo mejor que una estimación de valor calculado
Esto se debe a que el valor de expectación pondera los valores Q por la verdadera distribución de políticas. Al hacer esto, la esperada Sarsa corrige la diferencia entre la política empírica y la política empírica. distribución y la verdadera distribución política. En lugar de ponderar los valores Q por la verdadera distribución de las políticas, nosotros
puede sopesarlos mediante una política arbitraria,
El valor de aprendizaje fuera de las políticas pondera los valores Q por una política arbitraria. Esta ligera modificación nos permite estimar el valor bajo cualquier política que nos guste. Es interesante pensar en la SARSA esperada como un caso especial de aprendizaje fuera de política, utilizado en la evaluación dentro de la política. ¿Qué nos dice la perspectiva sobre el aprendizaje fuera de la política acerca de esto?
Para responder a esta pregunta, examinaremos algún estado donde se cruzan múltiples rutas de experiencia. En este estado, múltiples rutas de experiencia se intersecan. Las acciones que salen del estado se asocian con diferentes valores Q. Si re-evaluamos los valores Q, también re-evaluamos las rutas que pasan por ellos. En cualquier punto en el que se vuelvan a considerar las rutas intersecadas, las rutas más representativas de la distribución fuera de la política hacen mayores contribuciones al valor estimado. Mientras tanto, las rutas con baja probabilidad de contribuir aportan pequeñas contribuciones en muchos casos. En ciertos casos, un agente necesita obtener experiencia dentro del marco de una política subóptima (por ejemplo, para mejorar la). Utilizamos un tipo de aprendizaje fuera de la política llamado aprendizaje Q. El aprendizaje Q estima el valor bajo la política óptima seleccionando el máximo valor Q. El aprendizaje Q pasa por todas las rutas excepto las más valoradas. Las rutas restantes son las que seguirá el agente en prueba. Este tipo de aprendizaje de valor conduce a menudo a una convergencia más rápida que los métodos dentro de la política. Utilice el Playground al final de este artículo para comparar diferentes enfoques como el Doble Q-Learning. El problema con el aprendizaje Q es que da estimaciones de valor sesgadas. Más específicamente, es demasiado optimista
en presencia de recompensas ruidosas. He aquí un ejemplo donde Q-learning falla:
Usted va a un casino y jugar a cien máquinas tragamonedas. Es su día de suerte: usted golpeó el premio mayor en la máquina 43. Ahora, si usted utiliza
Q-learning para estimar el valor de estar en el casino, usted elegirá el mejor resultado sobre las acciones de jugar ranura
máquinas.
Usted terminará pensando que el valor del casino es el valor del premio mayor ... y decidir que el casino es un gran
¡Dónde estar! A veces el mayor valor Q de un estado es grande por casualidad; elegirlo sobre otros hace que la estimación del valor sea parcial. manera de reducir este sesgo es tener un amigo visitar el casino y jugar el mismo conjunto de máquinas tragamonedas. Entonces, preguntarles lo que su
las ganancias estaban en la máquina 43 y utilizar su respuesta como su estimación de valor. No es probable que ambos ganaron el premio mayor en el
la misma máquina, por lo que esta vez no terminará con una estimación demasiado optimista. Llamamos a este enfoque doble Q-learning. Es fácil pensar en Sarsa, Sarsa esperada, Q-learning, y Q-learning doble como algoritmos diferentes. Pero
como hemos visto, son simplemente diferentes maneras de estimar V ( s t + 1 ) V(s_{t+1}) V(st+1 ) en una actualización TD. Métodos en política Sarsa utiliza el valor Q asociado con una t + 1 a_{t+1} una t + 1 para estimar el valor del siguiente estado. Sarsa utiliza una expectativa sobre los valores Q para estimar el valor del siguiente estado. Q-values por una política arbitraria. El algoritmo Q-learning estima el valor bajo la política óptima seleccionando el valor máximo de Q. El doble Q-learning selecciona la acción más eficaz y luego estima su valor con dos valores diferentes de Q. La intención detrás de este enfoque es revaluar las decisiones tomadas. Reasignación de rutas mediante Monte Carlo. Pregunta natural: ¿Podemos lograr el mismo efecto de reasignación usando Monte Carlo?
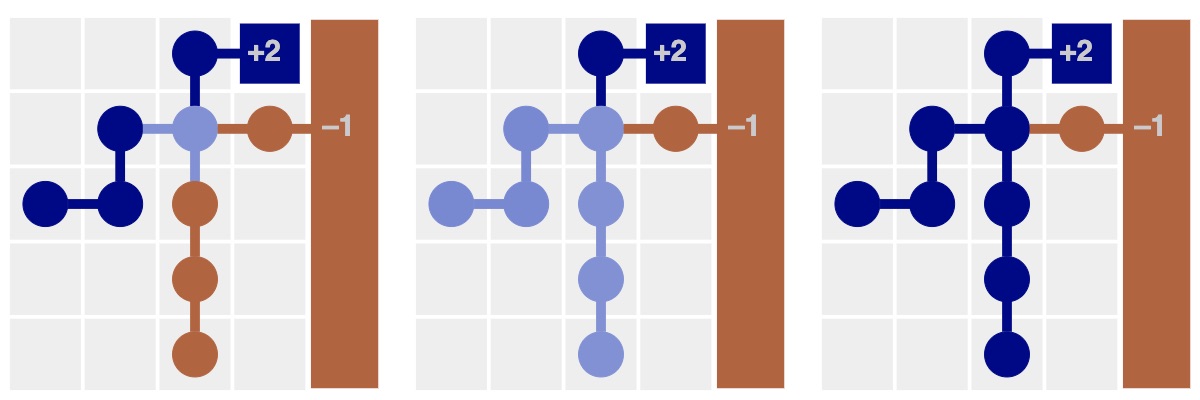
Sí, pero sería más complicado y implicaría volver a evaluar la experiencia del agente completo. Métodos TD revaluarian individualmente las transiciones en lugar de hacerlo por episodios. Esto hace los métodos TD mucho más cómodos para aprender fuera de la política. Fusión de rutas con aproximadores de funciones. Hasta ahora, hemos aprendido un parámetro —el valor estimado— para cada estado o cada par de acción-estado. Esto funciona bien en ejemplos simples pero los problemas de aprendizaje profundo tienen un gran o infinito número de estados, lo que hace difícil almacenar estimaciones de valor para cada estado. Las funciones de valor tabular mantienen estimaciones independientes de valor para cada estado individual. Euclidianos promedios, una clase de aproximadores de función, conservaron la memoria y permitieron que los agentes generalizaran a estados no visitados. En su lugar, debemos forzar a nuestro estimador de valores a contar menos parámetros que estados. Podemos lograr esto mediante métodos de aprendizaje automático, como la regresión lineal, árboles de decisión o redes neuronales. Todos estos métodos caen bajo el ámbito de la aproximación de funciones. Desde una perspectiva de los caminos, podemos interpretar la aproximación de funciones como un método de fusionar caminos cercanos. ¿Qué nos refieren con “cerca”? En la figura superior tomamos una decisión implícita de medir “cerca” con la distancia euclidiana. Fue una buena idea porque la distancia euclidiana entre dos estados está altamente correlacionada con la probabilidad del agente de transicionar entre ellos.
Sin embargo, es fácil imaginarse casos en los que esta suposición implícita se rompe. Al añadir una sola barrera larga, podemos construir un caso donde la métrica de distancia euclidiana conduce a una mala generalización. El problema es que hemos fusionado malos caminos. Imagina cambiar la configuración de Cliff World agregando una barrera larga. Ahora, usando el promedio euclidiano conduce a actualizaciones de valor incorrectas. Fusionar los caminos equivocados. El siguiente diagrama muestra más explícitamente los efectos de fusionar los caminos equivocados. El promedio euclidiano es responsable de una generalización pobre, tanto Monte Carlo como TD realizan actualizaciones de valor ineficaces. Este error se agrava dramáticamente en Monte Carlo, mientras que no lo hace en TD. Hemos visto que las actualizaciones de valor en TD son más eficientes, pero el precio a pagar es que estas actualizaciones son mucho más sensibles a la generalización errónea. Implicaciones para el aprendizaje del refuerzo profundo mediante redes neuronales. Las redes neuronales profundas son quizás las funciones más populares en el aprendizaje de refuerzo, pero una propiedad atractiva es que no hacen suposiciones implícitas sobre si los estados están cerca o lejos. Al principio del entrenamiento, las redes neuronales, como los promedios, tienden a fusionar los caminos incorrectos de la experiencia. Una red neuronal sin entrenar podría hacer actualizaciones de valor inadecuadas como el promedio euclidiano. Sin embargo, con el avance del entrenamiento, las redes neuronales pueden realmente aprender a superar estos errores.
En el ejemplo de Cliff World, esperaríamos que una red neuronal completamente entrenada haya aprendido que las actualizaciones de valor en los estados por encima de la barrera no deben influir en los valores de los estados por debajo de la barrera. Esto es algo que la mayoría de las otras funciones aproximantes no pueden hacer. Una razón por la cual el aprendizaje profundo RL es tan interesante! Una métrica de distancia aprendida por una red neuronal: Azul más claro se acerca a ser más distante. El agente, capacitado para capturar objetos utilizando un brazo robótico, tiene en cuenta las barreras y la longitud del brazo al medir la distancia entre dos estados. TD o TD? Hasta ahora hemos visto cómo el aprendizaje TD supera al Monte Carlo mediante la fusión de caminos de experiencia. Además, hemos visto que fusionar rutas es una espada de doble filo: cuando las actualizaciones de funciones causan malas actualizaciones de valor, el aprendizaje TD puede empeorarse. Sin embargo, en los últimos años, la mayoría del trabajo en RL ha preferido el aprendizaje TD al Monte Carlo. En realidad, muchos enfoques de RL utilizan actualizaciones de valor TD. Dicho esto, hay muchas otras formas de utilizar el Monte Carlo para el aprendizaje de refuerzo. Este artículo se centra en la estimación de valor con Monte Carlo, pero también puede utilizarse para la selección de políticas como en Silver et al. Ya que ambos, Monte Carlo y TD, tienen propiedades deseables, ¿por qué no intentar construir un estimador de valor que es una combinación de ambos? Este es el razonamiento detrás del aprendizaje TD( ♥ ♥ ♥ ♥). Es una técnica que simplemente interpola (usando un coeficiente entre las actualizaciones de Monte Carlo y TD) En el límite en que ♥ = 0 ♥=0, recuperamos la regla de actualización de TD.
Mientras tanto, cuando TD( ♥ ♥ ♥ ♥) funciona mejor que el Monte Carlo o el aprendizaje de TD por sí solo. Los investigadores a menudo mantienen constante el coeficiente de lambda al entrenar un modelo de RL profundo. Sin embargo, si pensamos que el Monte Carlo aprendizaje es mejor temprano en la formación (antes de que el agente haya aprendido una buena representación del estado) y el aprendizaje TD es mejor más adelante (cuando es más fácil beneficiarse de la fusión de caminos), tal vez el mejor enfoque es annealarlo. Nos ayuda a entender por qué el aprendizaje basado en recompensas puede ser beneficioso, por qué puede ser efectivo para el aprendizaje fuera de los esquemas establecidos y por qué pueden surgir desafíos al combinarlo con aproximadores de funciones. Encouragemos a usar el juego infantil Gridworld para elaborar sobre estas ideas o para realizar su propio experimento.