El Grand Tour es una técnica clásica de visualización de datos de alta dimensión, que proyecta conjuntos de datos y ofrece una proyección fácil para cualquier vista posible del mismo. A diferencia de métodos modernos de proyección no lineales como t-SNE y UMAP, el Grand Tour es un método lineal en su núcleo. En este artículo, mostramos cómo aprovechar la línea recta del Grand Tour para habilitar una serie de capacidades útiles exclusivamente para visualizar el comportamiento de redes neuronales profundas. Concretamente, presentamos tres casos de uso interesantes: visualizar el proceso de entrenamiento mientras la red cambia de peso, visualizar el comportamiento de capa en capa como los datos atraviesan la red y visualizar tanto cómo se forman ejemplos contradictorios como cómo engañan a una red neuronal.
Introducción Las redes neuronales profundas suelen obtener el mejor rendimiento en competiciones de aprendizaje supervisado, como el Reto de reconocimiento visual a gran escala de ImageNet (ILSVRC). Sin embargo, sus procesos de decisión y entrenamiento son notoriamente difíciles de interpretar. En este artículo, presentamos un método para visualizar las respuestas de una red neuronal que aprovecha las propiedades de redes neuronales profundas y las propiedades del Grand Tour. En particular, nuestro método nos permite razonar más directamente sobre la relación entre los cambios en los datos y los cambios en la visualización resultante. Como mostraremos, esta correspondencia de datos a visualización es central para el método que presentamos, especialmente cuando se compara con otros métodos no lineales como UMAP y t-SNE. Aunque las redes neuronales profundas claramente no son procesos lineales, a menudo lo que hacemos es limitar su no linealidad a un pequeño conjunto de operaciones. Esto nos permite seguir razonando sobre su comportamiento. Mejorando el contexto y proporcionando más consistencia, debería ser posible saber cómo variaría la visualización si los datos hubieran sido diferentes en alguna manera específica. Para ilustrar la técnica que vamos a presentar, entrenamos profundamente modelos de red neuronal (DNN) con tres conjuntos de datos comunes de clasificación de imágenes: MNIST, fashion-MNIST y CIFAR-10. La figura siguiente muestra un diagrama funcional sencillo de la red neuronal que usaremos a lo largo del artículo. La red neuronal se compone de líneas (ambos convolucionales y totalmente conectadas), max-pooling y ReLU. Primero introducido por Nair y Hinton, ReLU calcula f ( x ) = m a x ( 0 , x ) para cada entrada en un vector. Los bloques de color son bloques de construcción (es decir, capas de red neuronal), los mapas de calor de escala gris representan la imagen de entrada o vectores de activación intermedia después de algunas capas. A pesar de que las redes neuronales son capaces de realizar maravillosas clasificaciones, en realidad solo son tuberías de funciones relativamente simples. Para imágenes, la entrada es una matriz 2D de valores escalares para imágenes a escala de grises o tripletas RGB para imágenes coloreadas.
Cuando sea necesario, siempre se puede aplanar el array 2D en un vector dimensional. De igual manera, los valores intermedios después de cualquiera de las funciones en la composición, o activaciones de las neuronas después de una capa, también se pueden ver como vectores en R n, donde n es el número de neuronas en la capa. El softmax, por ejemplo, puede ser visto como un vector de 10 componentes cuyos valores son positivos reales. Esta visión vectorial de los datos en la red neural no solo nos permite representar datos complejos en una forma matemáticamente compacta, sino que también nos indica cómo visualizarlos de manera más efectiva. La mayoría de las funciones simples caen en dos categorías: son transformaciones lineales de sus entradas (como capas completamente conectadas o convolucionales) o funciones no lineales relativamente sencillas que funcionan en función de los componentes (como activaciones sigmoidal o ReLU). Algunas operaciones, especialmente el max-pooling y el softmax, no caen en ninguna de las categorías. Volveremos a esto más tarde. La figura anterior nos ayuda a ver una sola imagen a la vez; sin embargo, no proporciona mucho contexto para entender la relación entre capas, entre diferentes ejemplos o entre diferentes etiquetas de clase. Para ello, los investigadores recurren a visualizaciones más sofisticadas. Usando la visualización para entender las DNNs, vamos a comenzar por considerar el problema de la visualización del proceso de entrenamiento de una DNN. Al entrenar redes neuronales, optimizamos los parámetros mediante el minimizado de una función de pérdida de valor escalar, típicamente a través de alguna forma de descenso de gradiente. Queremos que la pérdida siga disminuyendo, así que
monitorizamos toda la historia de las pérdidas de entrenamiento y pruebas durante las rondas de entrenamiento (o “epochs”), para asegurarnos de que la pérdida
La siguiente figura muestra un diagrama de la línea de la pérdida de entrenamiento para el clasificador MNIST. tendencia general cumple con nuestra expectativa a medida que la pérdida disminuye constantemente, vemos algo extraño alrededor de las épocas 14 y 21: la curva
¿Qué pasó? ¿Qué causó eso? Si separamos ejemplos de entrada por su verdadero
etiquetas/clases y trazar la pérdida por clase como arriba, vemos que las dos gotas fueron causadas por las clases 1 y 7; el modelo
aprende diferentes clases en momentos muy diferentes en el proceso de formación.
Aunque la red aprende a reconocer dígitos 0, 2,
3, 4, 5, 6, 8 y 9 al principio, no es hasta la época 14 que comienza a reconocer con éxito el dígito 1, o hasta la época 21 que
reconoce el dígito 7. Si supimos con anticipación que estamos buscando tasas de error específicas de la clase, entonces este gráfico funciona bien. ¿Qué pasa si realmente no sabíamos qué buscar? En ese caso, podríamos considerar visualizaciones de activaciones neuronas (por ejemplo, en
la última capa softmax) para todos los ejemplos a la vez, buscando encontrar patrones como comportamiento específico de clase, y otros patrones
Además. Si hubiera sólo dos neuronas en esa capa, un simple diagrama de dispersión bidimensional funcionaría. Sin embargo, los puntos
en la capa softmax para nuestros conjuntos de datos de ejemplo son 10 dimensionales (y en los problemas de clasificación a mayor escala este número puede ser
Tenemos que mostrar dos dimensiones a la vez (que no se escala bien, ya que el número de gráficos posibles crece
cuadráticamente), o podemos utilizar la reducción de la dimensión para mapear los datos en un espacio bidimensional y mostrarlos en un solo
gráfico. La última reducción de la dimensión es no lineal Técnicas modernas de reducción de la dimensión tales como t-SNE
y UMAP son capaces de realizar impresionantes hazañas de resumen, proporcionando imágenes bidimensionales donde puntos similares tienden a ser
Sin embargo, estos métodos no son particularmente buenos para entender el comportamiento de la neurona. las activaciones a una escala fina. Considere la característica intrigante antes mencionada sobre la diferente tasa de aprendizaje que el MNIST
El clasificador tiene en los dígitos 1 y 7: la red no aprendió a reconocer el dígito 1 hasta la época 14, el dígito 7 hasta la época 21.
calcular t-SNE, dinámica t-SNE, y proyecciones UMAP de las épocas donde ocurre el fenómeno que describimos. Considere ahora el
tarea de identificar este comportamiento específico de la clase durante el entrenamiento. Como recordatorio, en este caso, el comportamiento extraño sucede con
dígitos 1 y 7, alrededor de las épocas 14 y 21, respectivamente. Aunque el comportamiento no es sutil, lo digital se clasifica mal y resulta difícil identificarlo en ninguna de las parcelas que siguen. Sólo con una inspección cuidadosa podemos notar que, por ejemplo, en el gráfico UMAP, el número 1 agrupado en la parte inferior durante la época 13 se transforma en una característica similar al tentáculo durante la época 14. Las activaciones Softmax del clasificador MNIST con reducción de dimensión no lineal. Usa los botones de la derecha para destacar los números 1 y 7 en la parcela, o arrastra rectángulos alrededor de los gráficos para seleccionar una razón por la cual las incrustaciones no lineales fallan en el esclarecimiento de este fenómeno es que, para el cambio particular en los datos, el principio de correspondencia data-visual fracasa.
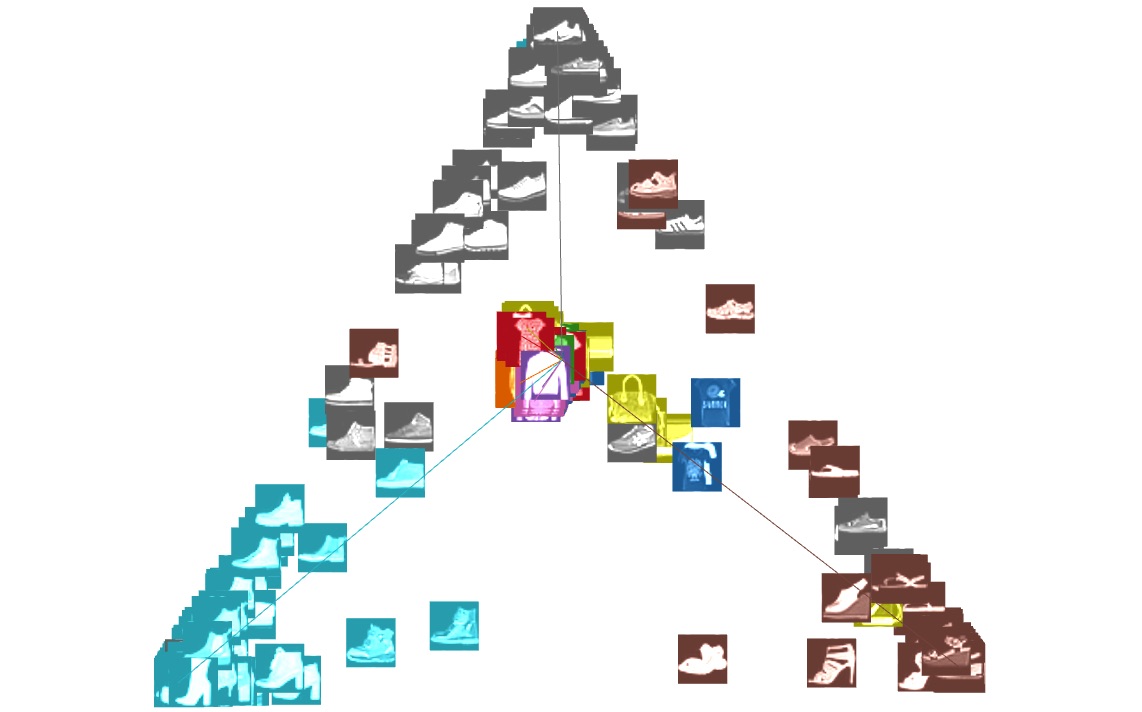
Más concretamente, el principio establece que las tareas de visualización específicas se deben modelar como funciones que transforman los datos; la visualización envía este cambio a imágenes y podemos estudiar hasta qué punto los cambios de visualización son fácilmente perceptibles. Idealmente, queremos que los cambios en los datos y la visualización coincidan en magnitud: un cambio casi imperceptible en la visualización debe deberse al menor cambio posible en los datos, y un cambio notable en la visualización debe reflejar un cambio significativo en los datos. Aquí, un cambio significativo ocurrió solo en un subconjunto de datos (por ejemplo, todos los puntos del número 1 durante la época 13 a 14), pero todos los puntos en la visualización se mueven dramáticamente. Para UMAP como para t-SNE, la posición de cada punto depende no trivialmente de la distribución completa de datos en tales algoritmos de incrustación. Esta propiedad es menos ideal para la visualización porque falla en la correspondencia data-visual, lo que hace difícil deducir el cambio subyacente en los datos del cambio en la visualización. Las incrustaciones con objetivos no convexos también tienden a ser sensibles a las condiciones iniciales. Por ejemplo, en MNIST, aunque la red neuronal comienza a estabilizarse a partir de la época 30, t-SNE y UMAP siguen generando proyecciones muy diferentes entre épocas 30, 31 y 32 (en realidad, todo el camino a 99). Técnicas de regularización temporal (como el T-SNE Dinámico) ayudan a mitigar esta inconsistencia, pero todavía tienen otros problemas de interpretabilidad. Ahora, vamos a considerar otra tarea: la identificación de clases. Para este ejemplo, usaremos los datos de la moda-MNIST y el clasificador, y consideraremos la confusión entre sandalias, zapatillas y botines. Si sabemos con anticipación que estas tres clases son probables de ser confundidas por el clasificador, podemos diseñar directamente una proyección lineal adecuada, como se puede ver en la última fila de la siguiente figura (encontramos esta proyección particular usando tanto el Grand Tour como la técnica de manipulación directa que describimos más adelante). El patrón en este caso es bastante notable, formando un triángulo. T-SNE se separa incorrectamente los agrupamientos de clase (posiblemente debido a un hiperparámetro inadecuado). UMAP separa con éxito las tres clases, sin embargo, no es posible distinguir entre la confusión en las etiquetas de clasificación en los episodios 5 y 10 (representados por un método lineal debido a la presencia de puntos cerca del centro del triángulo), y múltiples confusiones bidireccionales en épocas posteriores (pruebas con vacío de centro). Confusión en tres etiquetas en el conjunto de datos moda-MNIST.
Es importante resaltar que en contraste con los métodos no lineales, una proyección lineal construida puede ofrecer una visualización más adecuada del comportamiento del clasificador. Cuando tenemos la oportunidad, debemos preferir métodos para los cuales las modificaciones en los datos producen cambios predecibles y visualmente destacados en el resultado, así como reducciones lineales de dimensionalidad a menudo tienen esta propiedad. Aquí, revisitamos las proyecciones lineales descritas anteriormente en una interfaz donde el usuario puede navegar fácilmente entre diferentes episodios de entrenamiento. Además, se introduce otra capacidad útil disponible solo para los métodos lineales, la manipulación directa. Cada proyección lineal de n dimensiones a 2 dimensiones pueden ser representados por vectores 2-dimensionales con una interpretación intuitiva: son los vectores hacia donde se proyectará el vector base canónico en el espacio n-dimensional. En el contexto de proyectar la capa de clasificación final, esto es especialmente fácil de interpretar: son las direcciones a las que se clasificará una entrada con 100% de confianza a cualquier clase en particular. Si proporcionamos al usuario la capacidad de cambiar estos vectores arrastrando por la interfaz, los usuarios pueden configurar intuitivamente nuevas proyecciones lineales que permiten identificar patrones destacados en las ilustraciones anteriores. Por ejemplo, porque las proyecciones son lineales y los coeficientes de vectores en la capa de clasificación suman a uno, resultados de clasificación que son medio seguro entre dos clases se proyectarán a vectores que estén ubicados al medio camino entre la clase maneja. A partir de esta proyección lineal, podemos identificar fácilmente el aprendizaje del dígito 1 en la época 14 y el dígito 7 en la época 21. Esta propiedad en particular se ilustra claramente en el ejemplo de moda-MNIST siguiente. Esta proyección lineal muestra claramente la confusión del modelo entre sandalias , zapatillas , y botines . Del mismo modo, esta proyección muestra la verdadera confusión de tres vías sobre pullovers, abrigos y camisas. (Las camisas también se consiguen
Confundidos con camisetas/tops . ) Ambas proyecciones se encuentran por manipulaciones directas. Ejemplos que caen entre clases
indican que el modelo tiene problemas para distinguir los dos, tales como sandalias vs. zapatillas, y zapatillas vs. clases de botas de tobillo.
Tenga en cuenta, sin embargo, que esto no sucede tanto para sandalias vs. botines: no muchos ejemplos caen entre estas dos clases. Por otra parte, la mayoría de los puntos de datos se proyectan cerca del borde del triángulo. Esto nos dice que la mayoría de las confusiones suceden entre
dos de las tres clases, son realmente confusiones de dos vías. Dentro del mismo conjunto de datos, también podemos ver pullovers, abrigos y
camisas que llenan un plano triangular. Esto es diferente de la sandalia-sneaker-ankle-boot caso, ya que los ejemplos no sólo caen en la
límite de un triángulo, pero también en su interior: una verdadera confusión de tres vías. Del mismo modo, en el conjunto de datos CIFAR-10 podemos ver
confusión entre perros y gatos, aviones y barcos. El patrón de mezcla en CIFAR-10 no es tan claro como en la moda-MNIST,
porque muchos más ejemplos están mal clasificados. Esta proyección lineal muestra claramente la confusión del modelo entre gatos y perros . Del mismo modo, esta proyección muestra la confusión sobre aviones y naves . Ambas proyecciones se encuentran por manipulaciones directas. Aprovechando que sabíamos cuál tipo de clases debemos analizar, fue fácil diseñar proyecciones lineales para las tareas particulares. Sin embargo, ¿qué hacemos si no conocemos en anticipación qué proyección elegir, porque no sabemos muy bien qué buscar? El análisis de componentes principales (PCA) es el método lineal de reducción dimensionalidad fundamental, que consiste en proyectar los datos para preservar la mayor varianza posible. Sin embargo, la distribución de datos en capas softmax a menudo tiene varianza similar a lo largo de muchas direcciones del eje, porque cada eje concentra un número similar de ejemplos alrededor del vector de clase. Suponiendo que el conjunto de datos de entrenamiento está equilibrado en clases, sin embargo, si el conjunto de datos de formación no es equilibrado, PCA preferirá las dimensiones con más ejemplos, que podrían no ser útiles tampoco.
Como resultado, a pesar de que las proyecciones de PCA son interpretables y coherentes a lo largo del entrenamiento, los dos primeros componentes principales de las activaciones de softmax no son sustancialmente mejores que la tercera. Entonces, ¿quién debemos elegir? En lugar de PCA, propongo visualizar estos datos animando suavemente proyecciones aleatorias utilizando una técnica llamada Grand Tour. Mediante la rotación aleatoria, gira suavemente los puntos de datos alrededor del origen en el espacio de alta dimensión y luego los proyecta hacia abajo a 2D para mostrar. Aquí hay algunos ejemplos de cómo funciona Grand Tour con algunos objetos (de baja dimensión): En un cuadrado, el Grand Tour lo gira con una velocidad angular constante. En un cubo, el Grand Tour lo gira en 3D, y su proyección 2D nos permite ver cada cara del cubo. En un cubo 4D (un tesseract), la rotación ocurre en 4D y la vista 2D muestra cada posible proyección. Rotaciones de una plaza, un cubo y un tesseract El Grand Tour de la Capa Softmax La capa softmax es relativamente fácil de entender debido a que sus ejes tienen una fuerte semántica. Previamente hemos descrito que el eje i corresponde a la confianza de la red sobre la predicción de que la entrada dada pertenece a la clase i. Recientemente, hemos realizado un recorrido completo (Grand Tour) en la última época utilizando MNIST, moda-MNIST o CIFAR-10 dataset. Este Grand Tour nos permite evaluar cuantitativamente el rendimiento de nuestro modelo y comparar las dificultades relativas de clasificación de cada conjunto de datos. Resultados mostraron que los puntos de datos se clasifican con mayor confianza en MNIST, ya que los dígitos están más cerca de una de las esquinas del espacio softmax. Sin embargo, la separación no es tan limpia en moda-MNIST o CIFAR-10, con más puntos apareciendo dentro del volumen. Los métodos de proyección lineal dinámica naturalmente dan una formulación independiente de los puntos de entrada, lo que nos permite mantener la proyección fija mientras los datos cambian. Para nuestro ejemplo de trabajo, entrenamos cada red neuronal durante 99 épocas y registramos todas las actividades neuronales en un subconjunto de ejemplos de entrenamiento y pruebas. Utilizando el Grand Tour, podemos visualizar el proceso de entrenamiento real de estas redes.
Al principio, cuando se inicializan las redes neuronales al azar, todos los ejemplos se colocan cerca del centro del espacio softmax con pesos iguales para cada clase. A través del entrenamiento, los ejemplos se mueven a vectores de clase en el espacio softmax. El Grand Tour también nos permite comparar visualizaciones de los datos de entrenamiento y pruebas, dándonos una evaluación cualitativa sobre el sobreajuste en el conjunto de datos del MNIST. En CIFAR-10 hay una inconsistencia entre los equipos de entrenamiento y pruebas. Las imágenes de prueba continúan fluctuando, mientras que las imágenes del entrenamiento se acercan al área correspondiente de la clase. En el año 99, podemos ver una diferencia clara en la distribución entre estos dos conjuntos, lo cual indica que el modelo se adapta demasiado al conjunto de entrenamiento y no generaliza bien en el conjunto de pruebas. Con este enfoque de CIFAR-10, los puntos de color son más mezclados en la prueba que en el conjunto de entrenamiento. Esto contrasta con el enfoque de CIFAR-10 y MNIST o moda-MNIST, donde hay menos diferencia. El Gran Tour de Dinámica de Capas presenta técnicas para visualizar y manipular cualquier capa intermedia de una red neuronal, pero esto no es muy satisfactorio debido a dos razones: primero, mantener la proyección fija mientras los datos cambian en las capas es complicado, ya que diferentes capas tienen dimensiones diferentes. Además, las capas ocultas no tienen una semántica clara como la capa softmax, lo cual hace que su manipulación no sea intuitiva. Para abordar este problema, deberemos centrar más atención en cómo las capas transforman los datos que se les dan. Imaginemos una interpolación lineal de una capa a la siguiente, ya que tienen la misma dimensión. Además, el Gran Tour incorpora una rotación inherente en sí mismo. Por lo tanto, hay configuraciones diferentes que proporcionan una determinada imagen de la capa k k k y otra que proporciona la misma imagen para la capa k + 1 k+1 k+1 teniendo en cuenta el proceso A A A. En efecto, la interpolación simple falla al romper el principio de correspondencia entre datos-visuales: un cambio simple en los datos (como una rotación de 2D/180 grados) causa un cambio drástico en la visualización.
Esta observación sugiere una estrategia general para el diseño de visualizaciones: debemos ser lo más explícito posible sobre las partes de la entrada (o proceso) que queremos capturar en nuestras visualizaciones, y diferenciar lo que son artefactos puramente representativos que debemos descartar, y qué características reales debemos destacar en la visualización. Aquí, afirmamos que los factores de rotación en las transformaciones lineales de redes neuronales son significativamente menos importantes que otros factores como escalas y no linearidades. El Gran Tour es particularmente útil en este caso porque puede ser invariante a las rotaciones de los datos. Los componentes rotacionales en las transformaciones lineales de una red neuronal serán explícitamente invisibles. Lograr esto aprovechando un teorema central de álgebra lineal, el teorema de descomposición de valor singular (SVD), que demuestra que cualquier transformación lineal puede descomponerse en una secuencia de operaciones sencillas: una rotación, una escala y otra rotación. Esto significa que cualquier transformación lineal vista por el Gran Tour es equivalente a la transición entre x U x U x U y x U Σ - una escala simple (en sentido de coordenadas). En otras palabras, cualquier operación lineal (representada en base estándar) es una operación de escala con bases ortonormales adecuadamente seleccionadas en ambos lados. Esta es una forma natural, elegante y computacionalmente eficiente para alinear visualizaciones de activaciones separadas por totalmente conectadas (lineales) capas. Las capas convolucionales también son lineales. Al aplicar transformaciones lineales a características mapadas o analizando directamente la estructura circular de capas convolucionales, podemos rastrear comportamientos y patrones en la parte posterior de softmax en capas anteriores. Por ejemplo, en el conjunto de datos MNIST, vemos que las clases de zapatos (sandalias, tenis y botines) se separan del resto en la capa softmax. Regresando a las capas anteriores, podemos ver que esta separación ya ocurre en la capa 5. Con capas alineadas, podemos facilmente observar la separación temprana de los zapatos. Como escenario final de aplicación, mostramos cómo el Gran Tour también puede revelar el comportamiento de ejemplos contradictorios durante su procesamiento por una red neuronal. Para ilustrarlo, utilizamos el conjunto de datos MNIST y agreguémos perturbaciones a 89 dígitos 8s para engañarla a pensar que son 0s.
Anteriormente, podemos observar la dinámica de entrenamiento o la dinámica de capa. Fijamos una red neuronal bien entrenada y visualizamos el proceso de entrenamiento de ejemplos, ya que a menudo se generan por un proceso de optimización. Aquí, utilizamos el método de Signo de Grado Rápido. Debido a que Gran Tour es una técnica lineal, podemos atribuir cambios en las posiciones de los ejemplos contradictorios con el tiempo a cambios en la percepción de imágenes por la red neuronal, y no a artefactos potenciales de visualización. Examinemos cómo evolucionaron los ejemplos contradictorios para engañar a la red: A partir de esta vista de softmax, podemos ver cómo ejemplos contradictorios evolucionan desde 8s a 0s. Sin embargo, en el pre-softmax correspondiente, estos ejemplos contradictorios se detienen cerca del umbral de decisión de dos clases. Mostramos datos como imágenes para ver las imágenes reales generadas en cada paso, o puntos coloreados por etiquetas. A través de este entrenamiento contradictorio, la red finalmente declara con confianza alta que los insumos dados son todos 0s. Aunque todos los ejemplos contradictorios son clasificados finalmente como objetivo clase cero (digito 0s), algunos se desvían cerca del centro de la clase en algún momento (alrededor de la época 25) y luego, Comparando las imágenes reales de los dos grupos, observamos que aquellas que se desviaron son más interesantes. Sin embargo, lo más importante es lo que ocurre en las capas intermedias. En pre-softmax, por ejemplo, vemos que estos falsos 0s se comportan diferente a los auténticos 0s: viven más cerca del límite de decisión entre dos clases y forman una planificaciones en sí mismas. Las limitaciones de este estudio incluyeron la comparación de varias dimensiones técnicas de última generación de reducción con el Gran Tour, demostrando que los métodos no lineales no tienen tantas propiedades deseables como el Gran Tour para entender el comportamiento de las redes neuronales. Sin embargo, los métodos no lineales de última generación vienen con sus propias fuerzas. Cuando se trata de geometría, como en la comprensión de las confusiones multi-via en la capa softmax, los métodos lineales no son interpretables porque no conservan ciertas estructuras geométricas de los datos en la proyección. El enfoque principal, como cuando queremos agrupar los datos o necesitamos reducir la dimensionalidad para los modelos descendientes menos sensibles a la geometría, podríamos elegir métodos no lineales como UMAP o t-SNE porque tienen más libertad en la proyección de los datos y usualmente harán un mejor uso de las dimensiones menos disponibles.
El poder de la animación y la manipulación directa se utilizó al comparar proyecciones lineales con reducciones de dimensionalidad no lineales, pero aún hay debates sobre cuál es mejor entre pequeños múltiplos y animaciones en la literatura. Sin embargo, en nuestros escenarios, el uso de la animación se deriva naturalmente de la manipulación directa y del continuo de rotaciones para el Gran Tour para operar en. Modelos no secuenciales: En nuestro trabajo utilizamos modelos que son puramente Sin embargo, la descomposición de valor singular de las convoluciones del canal 2D puede computarse eficientemente y utilizarse directamente para la alineación, tal como hemos descrito previamente. En esta sección presentamos los detalles técnicos necesarios para manipular directamente el eje que controla los puntos de datos, así como cómo implementar la técnica de consistencia de proyección para transiciones de capas. Nuestra convención notacional es representar los datos de puntos como vectores de fila y toda una colección de datos presentada como una matriz, donde cada fila es un punto de datos y cada columna representa una característica/dimensión diferente. Cuando se aplica una transformación lineal a los datos, los vectores de fila (y la matriz de datos en general) se multiplican por la izquierda por la transformación matriz. Esto tiene el beneficio secundario de que al aplicar las multiplicaciones de matriz en una cadena, la fórmula lee de izquierda a derecha y se alinea con un diagrama conmutativo. Por ejemplo, cuando una matriz de datos X es multiplicada por una matriz M para generar Y, escribimos XM = Y en la fórmula, donde las letras tienen el mismo orden en el diagrama: X M Y. Además, si la SVD de M es M = U • V T , tenemos XU • VT = Y y el diagrama X U V T Y se corresponde con X U V T → Y. Las manipulaciones directas que presentamos anteriormente proporcionan control explícito sobre las posibles proyecciones para los puntos de datos. Presentamos dos modos: el modo del eje (o manejo directo de un grupo de puntos de datos a través de su centroide, conocido como el modo del punto de datos). Preferimos el modo de eje cuando la dimensionalidad y semántica del eje son discutidos en Layer Dynamics, ya que podemos ver un mango del eje como un punto ficticio especial dentro del conjunto de datos. Primero introduciremos el modo del eje. Como se muestra en el siguiente diagrama, e i e_i ei pasa a través de un Grand ortogonal
Matriz giratoria G T GT GT para producir una versión rotada de sí mismo, e i ~ \tilde{e_i} ei ~ . Entonces,
conserva sólo las dos primeras entradas de e ~ \tilde{e_i} ei ~ y da la coordenada 2D de la manija a mostrar en la trama, (
x , y i ) ( x_i , y_i ) ( xi ,yi ). e i G T e i ~ η 2 ( x i , y i ) e_i \overset{GT?mapsto} \tilde{e_i}
(x_i, y_i) e i G T e i ~ 2 ( x i, y i ) Cuando el usuario arrastra una manija de eje en el
lona de pantalla, inducen un cambio delta Δ = (d x, d y ) \Delta = (dx, dy) Δ = (dx, dy) en el plano x y xy xy. de la manija se convierte en: ( x i ( n e w ) , y i ( n e w ) ) ) : = ( x i + d x , y i + d y ) ( x_i®(new)} , y_i®(new)} ) := ( x_i+dx,
y_i+dy) (xi(nuevo) ,yi(nuevo) ):=(xi +dx,yi +dy) Tenga en cuenta que x i x_i xi y y i y_i yi son las dos primeras coordenadas del eje
mango en dimensiones altas después de la rotación Grand Tour, por lo que un cambio delta en ( x i , y i ) ( x_i, y_i ) ( xi ,yi ) induce un delta
cambiar Δ ~ : = ( d x , d y , 0 , 0 , ) \tilde{Delta} := (dx, dy, 0, 0, \cdots) : = (dx, dy,0,0,) en e ~ \tilde{e_i} ei ~ :
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
rotación cercana Grand Tour que respeta este cambio, primero tenga en cuenta que e i ~ \tilde{e_i} ei ~ es exactamente el i t h Ít} ith
fila de Grand Tour ortogonal matriz G T GT GT Recordar que la convención es que los vectores están en forma de fila y lineal
Las transformaciones son matrices que se multiplican a la derecha.
Así que e i e_i ei es un vector de fila cuya entrada i i-th i es 1 1 1 (y
0 0 0 s en otros lugares) y e ~ : = e i G T \tilde{e_i} := e_i \cdot GT ei ~ :=ei ♥GT es la fila i i i-th de G T GT GT . Naturalmente, queremos que la nueva matriz sea la G T GT GT original con su fila i t h ïth} ith sustituida por e i ~ + Δ ~
\tilde{e_itilde{\Delta} ei ~ , es decir, deberíamos añadir d x dx dx y d y dy dy a la (i , 1 ) (i,1) (i,1)-ésima entrada y (i ,
2 ) (i,2) (i,2)-o entrada de G T GT GT, respectivamente: G T ~ ← G T \widetilde{GT} \leftarrow GT ←GT G T ~ i , 1 ← G T i , 1 + d
x \widetilde{GT}_{i,1} \leftarrow GT_{i,1} + dx GT i,1 ←GTi,1 +dx G T ~ i , 2 ← G T i , 2 + d y \widetilde{GT}_{i,2} \leftarrow
GT_{i,2} + dy GT i,2 ←GTi,2 +dy Sin embargo, G T ~ \widetilde{GT} GT no es ortogonal para arbitrario ( d x , d y ) (dx, dy) (dx, dy). Para encontrar una aproximación a G T ~ \widetilde{GT} GT que es ortogonal, aplicamos la ortonormalización Gram-Schmidt en la
filas de G T ~ \widetilde{GT} GT , con la fila de i t h ïth} ith considerada en primer lugar en el proceso Gram-Schmidt: G T ( n e w ) : =
GramSchmidt ( G T ~ ) GT®(new)} := \textsf{GramSchmidt}(\widetilde{GT} GT(new):=GramSchmidt(GT ) Tenga en cuenta que el i t h Í
ith fila se normaliza a un vector unitario durante el Gram-Schmidt, por lo que la posición resultante de la manija es e i ~ ( n e w ) =
normalizar (e ~ + Δ ~ ) \tilde{e_i}(nuevo)} = \textsf{normalizar}(\tilde{e_i} + \tilde{\Delta}) ei ~ (nuevo)=normalizar(ei ~ )
que puede no ser exactamente lo mismo que e ~ + Δ ~ \tilde{e_itilde{\Delta} ei ~ , como muestra la siguiente figura Sin embargo, para
cualquier Δ ~ \tilde{Delta} , la norma de la diferencia está limitada por arriba por Δ ~ tilde{\Delta , como el
la figura siguiente demuestra. . El modo de punto de datos Ahora explicamos cómo manipulamos directamente los puntos de datos. Técnicamente hablando, esto
método sólo considera un punto a la vez. Para un grupo de puntos, calculamos su centroide y manipulamos directamente este solo
punto con este método. Pensando más cuidadosamente sobre el proceso en modo eje nos da una manera de arrastrar cualquier punto. Recordar
que en modo eje, hemos añadido manipulación del usuario Δ ~ : = ( d x , d y , 0 , 0 , ) \tilde{Delta} := (dx, dy, 0, 0, \cdots)
:=(dx,dy,0,0,) a la posición de la manija del eje i t h ïth} ith e i ~ \tilde{e_i} ei ~ . Esto induce un cambio delta en
la fila de la Gran Tour G T GT GT. A continuación, como el primer paso en Gram-Schmidt, normalizamos esta fila: G
T i ( n e w ) : = normalizar ( G T ~ i ) = normalizar ( e i ~ + Δ ~ ) GT_i®(nuevo)} := \textsf{normalizar}(\widetilde{GT}_i) =
\textsf{normalize}(\tilde{e_i} + \tilde{\Delta}) GTi(new) :=normalize(GT i )=normalize(ei ~ ) Estos dos pasos hacen que el eje
se mueven de e ~ \tilde{e_i} e ~ a e i ~ ( n e w ) : = normalizar ( e ~ + Δ ~ ) \tilde{e_i®(nuevo)} :=
\textsf{normalize}(\tilde{e_itilde{\Delta}) ei ~ (new):=normalize(ei ~ ). Mirando la geometría de este movimiento, el
“add-delta-then-normalize” en e ~ \tilde{e_i} ei ~ es equivalente a una rotación de e ~ \tilde{e_i} ei ~ hacia e i ~ ( n
e w ) \tilde{e_iä(new)} ei ~ (new), ilustrado en la figura de abajo. Esta interpretación geométrica puede ser directamente generalizada
a cualquier punto de datos arbitrarios. La figura muestra el caso en 3D, pero en el espacio dimensional superior es esencialmente el mismo, ya que
los dos vectores e i ~ \tilde{e_i} ei ~ y e i ~ + Δ ~ \tilde{e_itilde{\Delta} ei ~ solo abarcan un 2-subespacio. Ahora tenemos
una intuición geométrica agradable sobre la manipulación directa: arrastrar un punto induce una rotación simple Las rotaciones simples son rotaciones
con sólo un plano de rotación.
en el espacio de alta dimensión. Esta intuición es precisamente la forma en que implementamos nuestra
manipulación en puntos de datos arbitrarios, que especificaremos como a continuación. Generalizar esta observación desde la manija del eje a
punto de datos arbitrarios, queremos encontrar la rotación que mueve el centroide de un subconjunto seleccionado de puntos de datos c ~ \tilde{c} c~
a c ~ ( n e w ) : = ( c ~ + Δ ~ )
tilde{c / tilde{c} + \tilde{\Delta c~(new):=(c)c/c En primer lugar, el ángulo de rotación se puede encontrar por
sus similitudes de coseno: = arccos ( • c ~ , c ~ ( n e w ) • • • • • • • • • • c ~ ( n e w ) • • \theta = \textrm{arccos}(
\frac{\langle \tilde{c}, \tilde{c}(new)} \rangletilde{c \cdot tilde{c(new) )
A continuación, para encontrar la forma de matriz de la rotación, necesitamos una base conveniente. ser un cambio de la matriz de base (ortonormal) en la que las dos primeras filas forman el intervalo de 2 subespacios ( c ~ , c ~ ( n e w ) )
\textrm{span}(\tilde{c}, \tilde{c{(new)}) span(c~,c~(new)). Por ejemplo, podemos dejar que su primera fila se normalice ( c ~ )
\textsf{normalizar}(\tilde{c}) normalizar(c~), segunda fila para ser su complemento ortonormal normalizar ( c ~ ( n e w ) )
\textsf{normalizar}(\tilde{c}(new)}_{\perp}) normalizar(c(new) ) en el intervalo ( c ~ , c ~ ( n e w ) ) \textrm{span}(\tilde{c},
\tilde{c(new)}) span(c~,c~(new)), y las filas restantes completan todo el espacio: c ~ ( n e w ) : = c ~ − â â € ~ c â € â € â € c
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
normalizar ( c ~ ( n e w ) ) P ] Q := \begin{bmatrix} \cdots \textsf{normalizar}(\tilde{c} \cdots ♥ \cdots
\textsf{normalizar}(\tilde{c{(new)}_{\perp}) \cdots ♥ P \end{bmatrix} P:= normalize(c~)normalize(c(new) )P donde P
P P completa el espacio restante. Haciendo uso de Q Q Q, podemos encontrar la matriz que gira el espacio plano ( c ~ , c ~ ( n e w )
) \textrm{span}(\tilde{c}, \tilde{c{(new)}) span(c~,c~(new)) por el ángulo فارسى \theta فارسى:
P =: Q T R 1 , 2 ( فارسى ) Q \rho = Q ^T \begin{bmatrix} \cos \theta& \sin \theta& 0& \cdots/23370/ -\sin \theta&
\cos \theta& 0& 0& \cdots/23370/ 0& \vdots& \vdots& \vdots& & I& \end{bmatrix} Q =: Q^T R_{1,2}(\theta) Q
La nueva matriz del Gran Tour es el producto de la matriz de la matriz de la
G T GT GT original y G T ( n e w ) : = G T ( nuevo )} := GT \cdot \rho GT ( nuevo ): = GT Ahora deberíamos ser capaces de
ver la conexión entre el modo del eje y el modo del punto de datos. En el modo del punto de datos, encontrar Q Q Q puede ser hecho por Gram-Schmidt:
primera base c ~ \tilde{c} c~, encontrar el componente ortogonal de c ~ ( n e w ) \tilde{c{(new)} c~(new) in span ( c ~ , c ~ (
n e w ) ) \textrm{span}(\tilde{c}, \tilde{c{(new)}) span(c~,c~(new)), tome repetidamente un vector aleatorio, encuentre su ortogonal
componente a la extensión de los vectores de base actuales y añadirlo al conjunto de base. En modo eje, el i t h ïth} ith-row-first
Gram-Schmidt hace la rotación y el cambio de la base en un paso. es una función ReLU, la activación de salida es X l = R e L U ( X l − 1 ) X+l} = ReLU(X+l-1}) X l = R e L U ( X l − 1 ) . ReLU no cambia la dimensionalidad y la función se toma coordine sabiamente, podemos animar la transición por un simple
interpolación lineal: para un parámetro de tiempo t • [ 0 , 1 ] t \in [ 0,1] t • [ 0 , 1 ] , X ( l − 1 ) → l ( t ) : = ( 1 − t ) X l − 1
+ t X l X+(l-1) \to l}(t) := (1-t) X+t X+l} X ( l − 1 ) → l ( t ) : = ( 1 − t ) X l − 1 + t X l Capas lineales
Las transiciones entre capas lineales pueden parecer complicadas, pero como vamos a mostrar, esto viene de elegir bases de desajuste en
Si X l = X l − 1 M Xâl} = Xâl-1} M X l = X l − 1 M donde M â € R m × n M \in \mathbb{Râm \times
n} M • R m × n es la matriz de una transformación lineal, entonces tiene una descomposición de valor singular (SVD): M = U • V T M = U
\Sigma V^T M = U • V T donde U • R m × m U \in \mathbb{RÃ m \times m} U â R m × m y V T â R n × n V^T \in \mathbb{RÃ n
V T R n × n son ortogonales, R m × n \ Sigma \in \mathbb{RÃ3m \times n} â Â R m × n es diagonal. Para U arbitrario
U U y V T V^T V T , la transformación en X l − 1 X®l-1} X l − 1 es una composición de una rotación ( U U U ), escala ( فارسى \Sigma
(V T V^T V T ), que puede parecer complicado. Sin embargo, considere el problema de relacionar el Gran Tour
la vista de la capa X l X~l} X l a la de la capa X l + 1 X~l+1} X l + 1 . El Grand Tour tiene un único parámetro que representa la
rotación actual del conjunto de datos. Dado que nuestro objetivo es mantener la transición consistente, nos damos cuenta de que U U y V T V^T V T tienen
esencialmente ninguna significación - son sólo rotaciones a la opinión que puede ser exactamente “cancelado” cambiando la rotación
parámetro del Grand Tour en cualquiera de las capas. Por lo tanto, en lugar de mostrar M M M , buscamos para la transición a animar sólo el
El efecto de la escala de coordenadas es similar a la de la ReLU después del cambio adecuado.
de base. Dado X l = X l − 1 U • V T X • l} = X • l-1} U \Sigma V ^ T X l = X l − 1 U • V T , tenemos ( X l V ) = ( X l − 1 U )
(Xl}V) = (Xl1}U)\Sigma ( X l V ) = ( X l − 1 U ) • Para un parámetro de tiempo t • [ 0 , 1 ] t \in [0,1] t • [ 0 , 1 ] , X ( l − 1
) → l ( t ) : = ( 1 − t ) ( X l − 1 U ) + t ( X l V ) = ( 1 − t ) ( X l − 1 U ) + t ( X l − 1 U
(Xl1}U) + t (Xl}V) = (1t) (Xl1}U) + t (Xl1} U \Sigma) X ( l − 1 ) → l ( t ) : = ( 1 − t ) ( X l − 1 U ) + t ( X l V )
) = ( 1 − t ) ( X l − 1 U ) + t ( X l − 1 U
capas. Con un cambio de representación, podemos animar una capa convolucional como la sección anterior. este cambio de representación implica aplanar la entrada y la salida, y repetir el patrón del núcleo en una matriz escasa M
R m × n M \in \mathbb{RÃ3m \times n} M â R m × n , donde m m m y n n n son las dimensiones de la entrada y salida
Este cambio de representación sólo es práctico para una pequeña dimensión (por ejemplo, hasta 1000), ya que necesitamos
resolver SVD para capas lineales. Sin embargo, la descomposición de valor singular de convoluciones 2D multicanal se puede calcular
eficientemente , que se puede utilizar directamente para la alineación. Capas de max-pooling Animar capas de max-pooling no es trivial
Porque max-pooling no es lineal Una capa de max-pooling es lineal o coordenadamente lineal. La reemplazamos por media-
común y escalar por la relación de la media al máx. Calculamos la forma de matriz de la agrupación media y usamos su SVD para
alinear la vista antes y después de esta capa. Funcionalmente, nuestras operaciones tienen resultados equivalentes a max-pooling, pero esto
Por ejemplo, la versión de max-pooling del vector [ 0 . 9 , 0 . 9 , 0 . Los valores [9, 1.0], [0.9, 0.9, 0.9, 1.0] y [0.9, 0.9, 0.9, 0.9, 1.0] no deben ser considerados para asignar crédito; sin embargo, nuestra aplicación les otorga aproximadamente el 25% del resultado en la capa inferior. Además, si disponemos de la SVD y el diagrama se alinea con la ecuación, concluimos que, aunque t-SNE y UMAP son muy potentes, a menudo no proporcionan las correspondencias necesarias y estas pueden provenir incluso de métodos simples como Gran Tour. El método Gran Tour que presentamos es particularmente útil cuando la interacción directa del usuario sea disponible o deseable. Creen que podrían diseñar métodos que resalten las mejores características de ambos mundos, utilizando la reducción de dimensionalidad no lineal para crear representaciones intermedias relativamente bajas de las capas de activación y utilizando el Gran Tour y la interacción directa para calcular la proyección final.