Este artículo es parte del hilo Circuits, un formato experimental que recoge artículos cortos invitados y comentarios críticos
Ahondando en el funcionamiento interno de las redes neuronales. Circuitos Hilo Una visión general de la visión temprana en la concepciónV1 Muchos importantes
los puntos de transición en la historia de la ciencia han sido momentos en los que la ciencia “zoomed pulg En estos puntos, desarrollamos un
visualización o herramienta que nos permite ver el mundo en un nuevo nivel de detalle, y un nuevo campo de la ciencia se desarrolla para estudiar la
Por ejemplo, los microscopios nos permiten ver células, lo que conduce a la biología celular. Las técnicas incluyendo la cristalografía de rayos X nos permiten ver ADN, lo que conduce a la revolución molecular. teoría.
Partículas subatómicas. Neurociencia. La ciencia se acercó. Estas transiciones no eran sólo un cambio en la precisión: eran
cambios cualitativos en lo que son los objetos de la investigación científica. Por ejemplo, la biología celular no es sólo más cuidadosa
zoología. Es un nuevo tipo de investigación que cambia drásticamente lo que podemos entender. Los famosos ejemplos de este fenómeno
ha ocurrido a gran escala, pero también puede ser el cambio más modesto de una pequeña comunidad de investigación
estudiar su tema en un nivel de detalle de grano más fino. Micrographia de Hooke reveló un rico mundo microscópico como se ve a través de
un microscopio, incluyendo el descubrimiento inicial de células. Imágenes de la Biblioteca Nacional de Gales. microscopio insinuado en un nuevo mundo de células y microorganismos, las visualizaciones de redes neuronales artificiales han revelado
Las tentadoras insinuaciones y vislumbres de un rico mundo interior dentro de nuestros modelos (por ejemplo, ). Esto nos ha llevado a preguntarnos: ¿Es posible que
¿El aprendizaje profundo se encuentra en un punto de transición similar, aunque más modesto? Explicación del comportamiento de una red neuronal completa. Pero, ¿qué sucedería si utilizáramos un enfoque inspirado por la neurociencia? ¿Cómo serían los resultados si analizáramos individualmente las neuronas y sus pesos, como si fueran relevantes o importantes? ¿Y si dedicásemos miles de horas a rastrear cada neurona y sus conexiones?
¿Qué imagen de redes neuronales resultaría entonces? En contraste con la imagen típica de las redes neuronales como una caja negra, hemos encontrado que es bastante accesible en esta escala. No solo las neuronas parecen entenderse (incluso aquellas que inicialmente parecían inscrutables), sino que los circuitos de conexiones entre ellas parecen corresponder a algoritmos significativos. Se puede observar una forma de círculo montada a partir de curvas, una imagen de perro montada a partir de ojos, una imagen de automóvil compuesta por ruedas y ventanas, incluso se han encontrado circuitos implementando lógica simple: casos en los que la red implementa AND, OR o XOR sobre características visuales de alto nivel. En las últimas décadas, hemos visto muchas imágenes y análisis increíbles que sugieren un mundo ricamente dotado de características internas en redes neuronales modernas. Arriba, vemos una imagen de DeepDream, que ha provocado una gran cantidad de emoción en este ámbito. Este ensayo introduce un alto nivel de nuestro pensamiento y algunos principios de trabajo que hemos encontrado útiles en esta línea de investigación. Artículos futuros nosotros y nuestros colaboradores publicaremos exploraciones detalladas de este mundo interior. Solo rasgó la superficie de la comprensión de un solo modelo de visión. Si estas preguntas te resuenan, te invitamos a unirte a nosotros y a nuestros colaboradores en el proyecto Circuits, una colaboración científica abierta organizada en Distill. Las células se forman por formación de células libres, similar a la formación de cristales. Las células se forman por formación de células libres, similar a la
La imagen del libro de Schwann es del Deutsches Textarchiv Esta traducción/resumen de la obra de Schwann
las afirmaciones se pueden encontrar en muchos textos de biología; no pudimos determinar cuál es la fuente original de la traducción. Las dos primeras de estas afirmaciones son probablemente familiares, persistiendo en la teoría celular moderna. La tercera probablemente no es familiar, ya que
Resulta ser horriblemente incorrecto. Creemos que hay mucho valor en articular una versión fuerte de algo que uno puede
creen que es cierto, aunque sea falso como la tercera afirmación de Schwann.
En este espíritu, ofrecemos tres afirmaciones sobre neuronal
redes. Están destinados tanto como afirmaciones empíricas sobre la naturaleza de las redes neuronales, y también como afirmaciones normativas sobre cómo
Tres Alegaciones Especulativas sobre Redes Neurales Reclamación 1: Características Las características son lo fundamental
unidad de redes neuronales. Corresponden a direcciones. Por “dirección” nos referimos a una combinación lineal de neuronas en una capa. Se puede pensar en esto como un vector de dirección en el espacio vectorial de activaciones de neuronas en una capa dada. A menudo, lo encontramos
más útil para hablar de neuronas individuales, pero veremos que hay algunos casos en los que otras combinaciones son más
manera útil de analizar las redes, especialmente cuando las neuronas son “polisemánticas.” (Vea el glosario para una definición detallada.) las características pueden ser rigurosamente estudiadas y comprendidas. Las características son la unidad fundamental de las redes neuronales. Estas características pueden ser rigurosamente estudiadas y comprendidas.Reclamación 2: Circuitos Las características están conectadas por pesos, formando
circuitos. Un “circuito” es un subgráfico computacional de una red neural. Se trata de un conjunto de características y los bordes ponderados que son pesados. A menudo analizamos circuitos de tamaño reducido —por ejemplo, con menos de una docena de características—, aunque también pueden ser mucho más grandes. Estos circuitos pueden investigarse y entenderse de manera precisa. Las características están conectadas por pesos, formando circuito. Estos circuitos también pueden investigarse e interpretarse en detalle.
Claim 3: Universalidad Se forman características y circuito analógico entre modelos y tareas. Claim 3: También se forman características y circuito analógico entre modelos y tareas, entre modelos y tareas. La representación visual de parte de las características de la red neuronal del espacio puede representar, por ejemplo, un atlas de activación que visualiza parte de las características de la red neuronal espacial. Las afirmaciones son deliberadamente especulativas. En el libro, se han sugerido antes las afirmaciones en línea con (1) y (3), como discutiremos más adelante. Sin embargo, creemos que estas afirmaciones son importantes de considerar porque, si es cierto, podrían formar la base de un nuevo campo Las primeras capas de las redes neuronales presentan características como detectores de bordes o curvas, mientras que las capas posteriores tienen características como la detección de jerarquías de caracteristicas significativas. Sin embargo, existe una división en la comunidad científica sobre si esto es verdadero o no, ya que algunos investigadores creen que las redes neuronales analizan solo aspectos texturales, mientras que otros piensan que pueden interpretar características significativas. Sin embargo, muchos documentos han sido escritos descubriendo caracteristicas que parecen ser relevantes en diferentes dominios, lo que sugiere que las redes neuronales pueden entender más de la textura. A pesar de que estos documentos no expresan una visión muy clara sobre el tema, cientos de horas de análisis a redes neuronales nos han llevado a creer que las neuronas son comprensibles en general, aunque no siempre lo son de manera intuitiva. Por ejemplo, inicialmente parecían extrañas las neuronas que analizan la alta-baja frecuencia, pero en retrospectiva, son simples y elegantes. Ejemplo 1: Detectores de curvas Las neuronas de detección de curvas se pueden encontrar en cada modelo de visión no trivial que hemos examinado cuidadosamente. Estas unidades son interesantes porque se extienden por el límite entre las características que la comunidad está de acuerdo en general existen (por ejemplo, borde
detectores) y características para las que hay un escepticismo significativo (por ejemplo, características de alto nivel como oídos, automóviles, y
Nos centraremos en detectores de curvas en capas mixtas3b , una capa temprana de InceptionV1. Estas unidades respondieron a curvas
líneas y límites con un radio de alrededor de 60 píxeles. También son ligeramente excitados adicionalmente por líneas perpendiculares a lo largo de
el límite de la curva, y prefieren los dos lados de la curva para ser diferentes colores. Detectores de curva se encuentran en
familias de unidades, con cada miembro de la familia detectando la misma característica de curva en una orientación diferente.
En conjunto abarcan toda la gama de orientaciones. Es importante distinguir los detectores de curvas de otras unidades que pueden parecer
En particular, hay muchas unidades que utilizan curvas para detectar un subcomponente curvado (por ejemplo, círculos,
espirales, curvas S, forma de reloj de arena, curvatura 3D, ...). También hay unidades que responden a formas relacionadas con la curva como líneas o
esquinas afiladas. No consideramos que estas unidades sean detectores de curvas. Pero, ¿estos “detectores de curvas” realmente detectan curvas? Dedicaremos todo un artículo posterior a explorar esto en profundidad, pero el resumen es que pensamos que la evidencia es bastante
fuerte. Ofrecemos siete argumentos, esbozados a continuación. Vale la pena señalar que ninguno de estos argumentos son específicos de la curva: son
una herramienta útil y general para probar nuestra comprensión de otras características también. Varios de estos argumentos — dataset
ejemplos, ejemplos sintéticos, y curvas de afinación — son métodos clásicos de neurociencia visual (por ejemplo ). se basan en circuitos, que vamos a discutir en la siguiente sección. Argumento 1: La visualización de características ayuda a optimizar la detección confiable de curvas por parte de los detectores. Esto establece una relación causal, ya que toda la información añadida en la imagen es para provocar que la neurona dispare más. Puedes obtener más información sobre la visualización de funciones aquí. Argumento 2: Imágenes como las de ImageNet pueden hacer que estas neuronas se disparen fuertemente cuando se trata de curvas confiables en su orientación esperada. En cambio, si se desplazan moderadamente generalmente son menos perfectas o curvas de orientación diferente.
Argumento 3: Las imágenes sintéticas también pueden ser utilizadas para evaluar los detectores de curvas. Estos responden como se espera a una gama de imágenes de curvas creadas con diferentes orientaciones, curvaturas y fondos. Sólo disparan cerca de la orientación esperada, y no reaccionan fuertemente para líneas rectas o esquinas afiladas. Argumento 4: Si tomamos ejemplos de conjuntos de datos que causan que una neurona se dispare y los giramos gradualmente, estas dejarán de disparar y los detectores de curvas en la siguiente orientación comenzarán a disparar. Esto muestra que pueden detectar versiones rotadas de la misma cosa. Argumento 5: Examinando el circuito utilizado por los detectores de curvas, podemos observar un algoritmo de detección de curvas fuera de los pesos. No vemos nada sugestivo de una segunda causa alternativa de disparo, aunque hay muchos pesos más pequeños que no Argumento 6: Los clientes que utilizan los detectores de curvas son características inherentes a las curvas (por ejemplo, círculos, curvatura 3D, espirales...). Los detectores de curvas son utilizados por estos clientes en el Argumento 7: Basándonos en nuestra comprensión de cómo son implementados los detectores de curvas, podemos hacer una reimplementación manual, poniendo a mano todos los pesos para volver a implementar la detección de curvas. Esto nos permite crear un algoritmo de detección de curvas comprensible, e imitar significativamente los detectores de curva originales. Excluir completamente la posibilidad de algún caso secundario raro donde los detectores de curvas disparan para un tipo diferente de estímulo parece establecer que (1) las curvas causan que estas neuronas se disparen, (2) cada unidad responde a las curvas en ángulos diferentes, y (3) si hay otros estímulos que los hacen disparar esos estímulos son raros o causan activaciones más débiles. En general, estos argumentos parecen cumplir con los estándares probatorios que entendemos se utilizan en neurociencia. La ciencia neurológica tiene tradiciones establecidas y conocimientos institucionales sobre cómo evaluar tales afirmaciones, detalle más en artículos posteriores sobre detectores de curvas y circuitos de detección de curvas. Ejemplo 2: Detectores de frecuencias bajas. Los detectores de curva son un tipo de característica intuitiva que podemos suponer que existen en redes neuronales, pero ¿qué hay de las características no intuitivas? Los detectores de frecuencia alta y baja son un ejemplo de una característica menos intuitiva.
Aunque en el principio pueden parecer complejas, al entender su función se vuelven bastante sencillas. Buscan patrones de baja frecuencia en un lado de su campo receptivo y patrones de alta frecuencia en el otro lado. Los detectores están presentes en familias de características que buscan lo mismo en diferentes orientaciones. ¿Detectores de frecuencia útiles para la red? Parecen ser uno de varios heurísticos para detectar los límites de los objetos, especialmente cuando el fondo está fuera de enfoque. En un artículo posterior, vamos a explorar cómo se utilizan en la construcción de redes neuronales para interrogar neuronas curvas también puede ser utilizado para estudiar neuronas de baja frecuencia con algunos ajustes — por ejemplo, Una vez más creemos que estos argumentos colectivamente proporcionan un fuerte apoyo a la idea de que realmente son una familia de detectores de contraste de alta-baja frecuencia. Ejemplo 3: Detector de Cabeza de Perro Invariante de Pose. Ambos los detectores de curvas y los detectores de frecuencia baja son características visuales de bajo nivel, que se encuentran en las primeras capas de InceptionV1. ¿Cuál es el estado de las características más complejas y avanzadas? Podemos analizar una unidad que creemos sea un detector de perros pose-invariante. De la misma manera que con cualquier neurona, podemos generar una visualización de características y coleccionar ejemplos de conjuntos de datos para su estudio. Sin embargo, la geometría... no es posible obtenerla, pero provee información valiosa sobre lo que está buscando y los ejemplos del conjunto de datos confirman esto. Es importante destacar que la visualización de características y los ejemplos de conjuntos de datos por sí solos ya constituyen un fuerte argumento. La visualización de características establece un enlace causal, mientras que los ejemplos del conjunto de datos prueban el uso de la neurona en la práctica y si hay un segundo tipo de estímulos a los que responde. Sin embargo, podemos utilizar otros métodos para analizar una neurona para soportar esta investigación.
Por ejemplo, podemos utilizar un modelo 3D para generar imágenes sintéticas de cabezas de perro desde diferentes ángulos. Los enfoques que hemos resaltado hasta ahora representan un gran esfuerzo para estas características más abstractas y avanzadas, pero los argumentos basados en el circuito –que discutiremos más adelante– seguirán siendo fáciles de aplicar y nos darán herramientas realmente poderosas para entender y probar características avanzadas que no requieren mucho esfuerzo. Neuronas Polisémanticas Este ensayo puede dar una imagen demasiado rosada: tal vez cada neurona produzca un concepto agradable, comprensible para el ser humano si uno seriamente lo investiga? Lamentablemente, esto no es el caso. Las redes neuronales a menudo contienen “neuronas polisemánticas” que responden a múltiples entradas no relacionadas. Por ejemplo, InceptionV1 contiene una neurona que responde a las caras de gato, frentes de coches y patas de gato. Para ser claro, esta neurona no está respondiendo a alguna comúnidad de coches y caras de gato . Característica
visualización nos muestra que está buscando los ojos y bigotes de un gato, para las piernas peludas, y para los frentes brillantes de los coches — no
todavía podemos estudiar tales características, caracterizando cada caso diferente que disparan, y razonar sobre
sus circuitos hasta cierto punto. A pesar de esto, las neuronas polisemánticas son un reto importante para la agenda de los circuitos, significativamente
limitar nuestra capacidad de razonar sobre las redes neuronales. ¿Por qué son las neuronas polisemánticas tan desafiantes? Si una neurona con cinco
diferentes significados se conecta a otra neurona con cinco significados diferentes, que es efectivamente 25 conexiones que no pueden ser
nuestra esperanza es que sea posible resolver las neuronas polisemánticas, tal vez “desplegando” una red
convertir las neuronas polisemánticas en rasgos puros, o redes de entrenamiento para no exhibir polisemanticidad en primer lugar. esencialmente el problema estudiado en la literatura de las representaciones disentangling, aunque en la actualidad la literatura tiende a
enfocarse en las características conocidas en los espacios latentes de los modelos generativos. Una pregunta natural a preguntar es por qué las neuronas polisemánticas
En la siguiente sección, veremos que parecen ser el resultado de un fenómeno que llamamos “superposición” donde un circuito se extiende
una característica a través de muchas neuronas, presumiblemente para empaquetar más características en el número limitado de neuronas que tiene disponible. Circuitos Las características están conectadas por pesos, formando circuitos. Estos circuitos también pueden ser rigurosamente estudiados y
Todas las neuronas de nuestra red se forman a partir de combinaciones lineales de neuronas en la capa anterior, seguidas por
ReLU.
Si podemos entender las características en ambas capas, ¿no deberíamos también ser capaces de entender las conexiones entre ellas? explorar esto, nos parece útil estudiar circuitos: sub-grafías de la red, que consiste en un conjunto de características estrechamente vinculadas y
La cosa notable es lo traducible y significativo que estos circuitos parecen ser como objetos de estudio. Cuando empezamos a buscar, esperábamos encontrar algo bastante desordenado. En cambio, hemos encontrado hermosas estructuras ricas, a menudo con
simetría a ellos. Una vez que usted entiende qué características que están conectando juntos, el número de punto flotante individual pesa en
su red neuronal se vuelve significativo! Usted puede leer literalmente algoritmos significativos fuera de los pesos. Vamos a analizar cómo se integran los detectores de curvas dentro del modelo, explorando sus características y su conexión con el resto. Los detectores de curva son principalmente desarrollados a partir de detectores anteriores menos avanzados, como detectores de líneas. Estos se utilizan para crear geometrías 3D complejas en la siguiente capa. Sin embargo, hay varias conexiones adicionales con otras características. Para esta introducción, vamos a centrar nuestra atención en la interacción entre los detectores de curva tempranos y los detectores de curva completos, y cómo un detector de curva simple se conecta con un detector más sofisticado en la misma orientación. Además, vamos a examinar cómo una convolución 5x5 es utilizada en nuestro modelo y cómo los pesos que conectan estas dos neuronas forman un conjunto de pesos 5x5. Esto se puede entender como buscar 'tangentes de curva' en cada punto a lo largo de la trayectoria. Esto es cierto para todos los detectores de curvas precoz y completo, con orientaciones similares. En cada punto de la trayectoria, el detector identifica la curva en una orientación similar.
De igual modo, las curvas en la dirección opuesta a la orientación son inhibidoras en cada punto de la trayectoria. Los detectores de curvas se excitan por los detectores anteriores con orientaciones similares... y se inhiben por los detectores anteriores con orientaciones opuestas. Es importante reflexionar aquí que estamos buscando pesos en la red neural, los cuales son significativos. Y la estructura se vuelve más rica cuanto más cerca se mira. Por ejemplo, si se observa un detector de curva precoz y un detector de curva completa con orientaciones similares, pero no exactamente la misma, es posible que tengan pesos positivos más fuertes en el lado de la curva que está más alineado. También vale la pena señalar cómo los pesos giran junto con la orientación del detector de curvas. La simetría del problema se refleja como una simetría en los pesos. Circuito que muestra este fenómeno es un 'circuito equivariante', y discutiremos sobre ello en más detalle en un artículo posterior. 2: Detección de cabeza de perro orientado. El circuito del detector de curvas es un circuito básico, que solo cubre dos capas. En esta sección, discutiremos un circuito complejo que abarca cuatro capas. Este circuito también nos enseñará sobre cómo las redes neuronales implementan invarianzas sofisticadas. Recuerda que una parte importante de lo que un modelo de ImageNet tiene que hacer es diferenciar animales diferentes. En particular, tiene que distinguir entre un centenar de diferentes especies de perros! Y así, no es de extrañar, desarrolla un
gran número de neuronas dedicadas a reconocer características relacionadas con el perro, incluyendo cabezas.
un circuito nos parece particularmente interesante: una colección de neuronas que manejan cabezas de perro frente a la izquierda y el perro
frente a la derecha. En tres capas, la red mantiene dos vías espejadas, detectando unidades análogas frente a
a la izquierda y a la derecha. En cada paso, estas vías tratan de inhibirse mutuamente, afilando el contraste. Finalmente, crea
neuronas invariantes que responden a ambas vías. Llamamos a este patrón “unirse sobre los casos”. La red detecta por separado
dos casos (izquierda y derecha) y luego toma una unión sobre ellos para crear unidades invariantes “multifaceted”. Tenga en cuenta que, porque los dos
las vías se inhiben entre sí, este circuito en realidad tiene algunas propiedades como XOR. Este circuito es sorprendente porque la red
fácilmente podría haber hecho algo mucho menos sofisticado. Podría crear neuronas invariantes al no preocuparse mucho por
donde los ojos, el pelo y el hocico fueron, y sólo buscando un revoltijo de ellos juntos. Pero en su lugar, la red ha aprendido a
separar los casos de izquierda y derecha y manejarlos por separado. Estamos un poco sorprendidos de que el descenso de gradiente podría aprender a
Para que quede claro, también hay vías más directas por las que varios constituyentes de cabezas influyen en estas cabezas posteriores. detectores, sin ir a través de las vías izquierda y derecha Pero este resumen del circuito sólo está rascando la superficie
Cada conexión entre neuronas es una convolución, por lo que también podemos ver donde una neurona de entrada excita la
el siguiente. Y los modelos tienden a hacer lo que usted podría haber esperado optimistamente. Por ejemplo, considere estas unidades 'cabeza-cuello'. Sólo la cabeza es detectable en la orientación correcta.
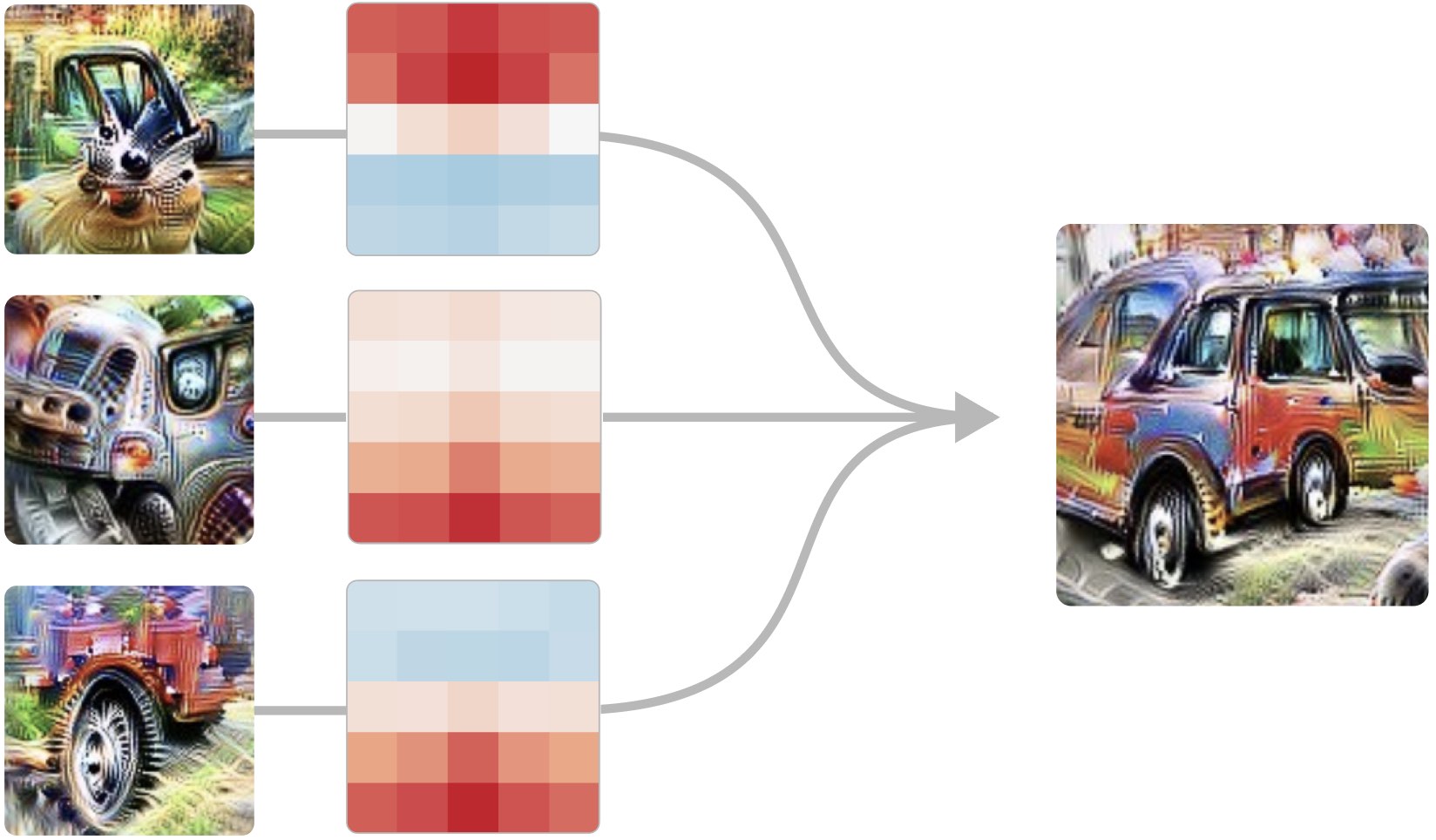
El paso de la unión también es interesante para observar detalles de red que no responden indiscriminadamente a las cabezas en ambas direcciones: las regiones de excitación se extienden en diferentes direcciones dependiendo de la orientación, lo que permite que los hocicos converjan en el mismo punto. Hay mucho más para decir sobre este circuito, por lo que planeamos volver a él en un artículo futuro y analizarlo en profundidad, incluyendo la prueba de nuestra teoría. Circuito 3: Coches en Superposición En mixto4c , una capa media-late de InceptionV1, hay una neurona de detección de coches. Utilizando características de las capas anteriores, busca ruedas en la parte inferior de su convolucional, pero luego el modelo hace algo extraño. En lugar de crear otro detector de coche puro en la siguiente capa, se extiende su característica de coche sobre una serie de neuronas que parecen estar haciendo principalmente otra cosa — en este circuito, sugieren que las neuronas polisemánticas son, en cierto sentido, deliberadas. Imagina un mundo donde el proceso de detección de coches y perros estaba profundamente entrelazado en el modelo por alguna razón, y como resultado, las neuronas polisemánticas fueron difíciles de evitar. Pero lo que estamos viendo aquí es que el modelo tenía una 'neurona pura' y luego la llamamos superposición del fenómeno. ¿Por qué haría tal cosa? Creemos que la superposición permite al modelo utilizar menos neuronas, conservándolas para tareas más importantes. Coocurre, el modelo puede recuperar con precisión la característica de perro en una capa posterior, lo que le permite almacenar la característica sin dedicar una neurona. Fundamentalmente, esta es una propiedad de los espacios de alto dimensión, que sólo permiten n vectores ortogonales, pero exponencialmente muchos vectores casi ortogonales. InceptionV1 y otros modelos hemos visto los mismos patrones abstractos una y otra vez. Equivarianza, como vimos con la curva Detectores. Unión sobre cajas, como vimos con el detector de cabeza de perro pose-invariante. Nos hemos visto que la superposición, a través del detector de coche, también se aplica en biología donde un patrón recurrente es un motivo útil en gráficos complejos como redes de transcripción o biológicas.
Estudiar motivos puede ser importante para entender las redes neuronales artificiales, ya que podemos apoyarnos en ellos para comprender todos los gráficos donde se repite el patrón. Es posible que la investigación de motivos sea más importante que la de circuitos individuales a largo plazo. Esperamos que las investigaciones sobre motivos tengan buen servicio primero construyendo una base sólida en los circuitos bien comprendidos. Características y circuitos análogos se forman mediante modelos e investigaciones. La característica más aceptada es que modelos entrenados en imágenes naturales aprenden filtros Gabor. Es probable que las mismas características también se forme en capas posteriores. Características análogas en múltiples capas parecerían naturalmente conectarse de la misma manera. Se ha sugerido antes que las características son universales (o «aprendizaje convergente»). Previous research has shown that different neural networks can develop highly correlated neurons and learn similar representations in hidden layers. Sin embargo, es deseable caracterizar varias características y demostrar rigurosamente que esas características — no sólo correlacionadas — se están formando en muchos modelos. Idealmente, uno quisiera encontrar características análogas sobre varias capas de múltiples modelos e investigar si la misma estructura de peso se forma entre ellos en cada modelo. Desafortunadamente, la única evidencia que podemos presentar hoy es anecdótica: simplemente no hemos gastado lo suficiente en estudios comparativos de características y circuitos para confirmar si esta observación es valida. Sin embargo, hemos visto que algunas características de bajo nivel parecen formarse a través de una variedad de arquitecturas de modelos de visión (como AlexNet, InceptionV1, InceptionV3 y redes residuales) y en modelos entrenados en Places365 en lugar de ImageNet. Además, hemos visto que estas características también se forman repetidamente en redes de convolutiones entrenadas desde cero en ImageNet. Detectores de curvas como los de AlexNet y InceptionV1 también han sido observados en este estudio.
Estos resultados nos llevan a sospechar que la hipótesis de universalidad es probablemente cierta, pero será necesario continuar trabajando para comprobar si la aparente universalidad de algunas características de visión de bajo nivel es la excepción o la regla. Si resulta que la hipótesis de universalidad es ampliamente cierta en redes neuronales, será tentador especular: los investigadores que trabajan en la intersección de la neurociencia y el aprendizaje profundo ya han demostrado que las unidades en modelos de visión artificial pueden ser útiles para modelar neuronas biológicas. Y algunas de las características que hemos descubierto en redes neuronales artificiales, como detectores de curvas, también se cree que existen en redes neuronales biológicas (por ejemplo). Esto parece ser una causa significativa de optimismo. Una posibilidad particularmente emocionante podría ser si las redes neuronales artificiales pudieran predecir características que hasta ahora se desconocían, pero luego podrían confirmarse en la biología (algunos neurocientíficos han sugerido que los detectores de frecuencia alta-baja podrían ser un candidato para esto). Si se pudiera realizar tal predicción, se trataría de una evidencia extraordinariamente fuerte para la hipótesis de la universalidad. Centrándonos en el estudio de los circuitos, ¿es verdadera la necesidad de la universalidad? A diferencia de las dos primeras afirmaciones, no sería completamente fatal para las investigaciones sobre circuitos si esta tercera resultara inexacta. Sin embargo, significaría informar en gran medida qué tipo de investigación tiene sentido. Imagínense los circuitos como una especie de 'biología celular' de especies diferentes: ¿tendría aún sentido estudiar cualquier circuito en particular, o nos limitaríamos al estudio estrecho de unos pocos tipos de circuitos muy importantes? De la misma manera, imagine un mundo donde cada especie tuviera una anatomía completamente diferente: ¿estudiaríamos otras cosas que los humanos y un par de animales domésticos? La hipótesis de la universalidad determina qué forma de investigación de circuitos tiene sentido. Se podría imaginar una especie de 'tabla periódica de características visuales' que observamos y catalogamos a través de los modelos. Si fuera mayormente falso, tendríamos que centrarnos en un puñado de modelos de importancia social y esperar que se detengan. También puede haber entre mundos, donde algunas lecciones se transfieren entre modelos pero otras necesitan ser aprendidas nuevamente.
Fue presentado el trabajo de Kuhn y establecimos una conexión a través de conversaciones con Tom McGrath en DeepMind. No existe consenso sobre cuáles son los objetos de estudio, qué métodos debemos utilizar para responder a ellos o cómo evaluar la investigación. En una reciente entrevista con Ian Goodfellow se dijo: 'No creo que tengamos el derecho interpretar'. Una de las cuestiones más difíciles en un campo pre-paradigmático es que no hay un sentido compartido de qué significa hacer interpretaciones o visualizaciones. En lo que respecta a la evaluación del trabajo sobre la interpretabilidad y la visualización, existen dos propuestas comunes para abordar esta cuestión: algunos investigadores quieren una referencia para interpretaciones que valide el método de interpretación; otros prefieren evaluar los métodos a través de estudios de usuario. Sin embargo, también se puede tomar prestado de un tercer paradigma: la ciencia natural. En este punto de vista, las redes neuronales son objeto de investigación empírica, posiblemente similar a un organismo en biología. Intentar obtener afirmaciones empíricas sobre una red dada que se mantenga al nivel de la falsificación es difícil, debido a que las redes neuronales son objeto increíblemente complicados y difíciles de formalizar exactamente lo que serían declaraciones interesantes acerca de ellos. De esta manera, obtenemos estándares de evaluación más orientados a si un método de interpretabilidad es útil en lugar de si estamos aprendiendo declaraciones verdaderas. Los circuitos se centran en pequeños subgráficos de una red neuronal para la que una investigación empírica rigurosa puede ser muy falsificable: por ejemplo, si entiende un circuito, debe poder predecir lo que cambiaría si se editan los pesos. En resumen, vemos a los investigadores que toman más este enfoque de las ciencias naturales, especialmente en la investigación de la interpretabilidad anterior. Especialmente dado que hay tanto trabajo de ML adyacente que adopta este marco! Una razón podría ser que es muy difícil hacer declaraciones robustamente verdaderas sobre el comportamiento de una red neuronal en su conjunto. Claro, el precio de esa rigidez consiste en que las declaraciones sobre los circuitos tienen un alcance limitado en comparación con... Si se confirma, estas podrían actuar como una especie de base epistemológica para la interpretabilidad. Parece que nos preocupa cierta ansiedad en la comunidad de interpretabilidad, ya que consideran que esta investigación es demasiado cualitativa.
Pero la lección del microscopio y la biología celular es que tal vez esto se espera, ya que el descubrimiento de las células fue un resultado cualitativo de la investigación y no impidió cambiar el mundo.